Rodzaje sppr. Systemy wspomagania decyzji (DSS) ogólna koncepcja DSS
Wstęp
Istnieje kilka definicji IDSS, które na ogół obracają się wokół tej samej funkcjonalności. V ogólna perspektywa, IDSS jest takim systemem, który pomaga decydentom (Decision Makers) w podejmowaniu tych właśnie decyzji, wykorzystując narzędzia do eksploracji danych, modelowania i wizualizacji, posiada przyjazny (G)UI, stabilny w jakości, interaktywny i elastyczny w ustawieniach.Dlaczego potrzebujemy DSS:
- Trudności w podejmowaniu decyzji
- Potrzeba dokładnej oceny różnych alternatyw
- Potrzeba predykcyjnej funkcjonalności
- Konieczność wielowątkowego wkładu (aby podjąć decyzję, potrzebne są wnioski oparte na danych, ekspertyzy, znane ograniczenia itp.)
Od początku lat 80. możemy już mówić o formacji Podklasy DSS takie jak MIS (Management Information System), EIS (Executive Information System), GDSS (Grupowe Systemy Wspomagania Decyzji), ODSS (Organizacyjne Systemy Wspomagania Decyzji) itp. (od indywidualnego do korporacyjnego), a wewnątrz można było wprowadzić dowolną logikę. Przykładem jest system GADS (Gate Assignment Display System) opracowany przez Texas Instruments dla United Airlines, który wspierał podejmowanie decyzji w Field Operations – przydzielanie bramek, ustalanie optymalnego czasu parkowania itp.
Pod koniec lat 80. pojawiły się PSSPR(Zaawansowane - Zaawansowane), co pozwalało na analizę typu „co by było, gdyby” i wykorzystywało bardziej zaawansowane narzędzia do modelowania.
Wreszcie, od połowy lat 90. zaczął się pojawiać i IDSS, które zostały oparte na narzędziach statystyki i uczenia maszynowego, teorii gier i innych złożonych modelowaniach.
Różnorodność DSS
Obecnie jest kilka sposobów Klasyfikacja DSS, opiszemy 3 popularne:Według obszaru zastosowania
- Biznes i zarządzanie (ceny, siła robocza, produkty, strategia itp.)
- Inżynieria (projektowanie produktu, kontrola jakości...)
- Finanse (pożyczki i pożyczki)
- Medycyna (leki, zabiegi, diagnostyka)
- Środowisko
Według proporcji danych\model(metoda Stephena Altera)
- FDS (File Drawer Systems - systemy zapewniające dostęp do niezbędnych danych)
- DAS (Systemy Analizy Danych - systemy do szybkiej manipulacji danymi)
- AIS (Analysis Information Systems - systemy dostępu do danych według rodzaju wymaganego rozwiązania)
- AFM(s) (modele księgowe i finansowe (systemy) - systemy do obliczania konsekwencji finansowych)
- RM(s) (Modele reprezentacji (systemy) - systemy symulacyjne, AnyLogic jako przykład)
- OM(s) (Modele optymalizacyjne (systemy) - systemy rozwiązujące problemy optymalizacyjne)
- SM(s) (modele sugestii (systemy) - systemy wnioskowania oparte na regułach)
Według rodzaju używanego instrumentu
- Model Driven - oparty na modelach klasycznych (modele liniowe, modele zarządzania zapasami, transportowe, finansowe itp.)
- Oparte na danych - na podstawie danych historycznych
- Communication Driven - systemy oparte na grupowym podejmowaniu decyzji przez ekspertów (systemy ułatwiające wymianę opinii i obliczanie średnich wartości eksperckich)
- Document Driven - zasadniczo indeksowane (często wielowymiarowe) przechowywanie dokumentów
- Wiedza napędzana - nagle, oparta na wiedzy. Co oznacza wiedza ekspercka i maszynowa
Chcę książkę reklamacyjną! normalne DSS
Pomimo tak różnorodnych możliwości klasyfikacji, wymagania i atrybuty DSS dobrze wpisują się w 4 segmenty:- Jakość
- Organizacja
- Ograniczenia
- Model

Osobno zwracamy uwagę na tak ważne atrybuty, jak skalowalność (w obecnym zwinnym podejściu nie można się bez niej obejść), możliwość przetwarzania złych danych, użyteczność i przyjazny interfejs użytkownika oraz niewymagające zasoby.
Architektura i projektowanie IDSS
Istnieje kilka podejść do architektonicznego przedstawiania DSS. Być może najlepszym opisem różnicy w podejściach jest „kto jest w co”. Mimo różnorodności podejść podejmowane są próby stworzenia jakiejś zunifikowanej architektury, przynajmniej na najwyższym poziomie.Rzeczywiście DSS można podzielić na 4 duże warstwy:
- Berło
- Modelowanie
- eksploracja danych
- zbieranie danych
Na poniższym schemacie przedstawiam moją wizję architektury wraz z opisem funkcjonalności i przykładowymi narzędziami:

Architektura jest mniej lub bardziej przejrzysta, przejdźmy do projektowania i faktycznej budowy DSS.
W zasadzie nie ma tu nauki o rakietach. Podczas budowania IDSS należy wykonać następujące kroki:
- Analiza domeny (właściwie, gdzie będziemy korzystać z naszego IDSS)
- Zbieranie danych
- Analiza danych
- Wybór modeli
- Analiza ekspercka\interpretacja modeli
- Wdrażanie modeli
- Ocena IDSS
- Wdrożenie IDSS
- Zbieranie opinii ( na każdym etapie, w rzeczywistości)

Istnieją dwa sposoby oceny IDSS. Najpierw przez macierz atrybutów, która została przedstawiona powyżej. Po drugie, zgodnie z listą kontrolną kryteriów, która może być dowolna i zależeć od konkretnego zadania. Jako przykład takiej listy kontrolnej podałbym:

Podkreślam, że to tylko IMHO i możesz zrobić sobie wygodną dla siebie listę kontrolną.
Gdzie jest uczenie maszynowe i teoria gier?
Tak, prawie wszędzie! Przynajmniej w warstwie modelarskiej.Z jednej strony istnieją domeny klasyczne, nazwijmy je „ciężkimi”, takie jak zarządzanie łańcuchem dostaw, produkcja, zapasy i tak dalej. W ciężkich domenach nasze ulubione algorytmy mogą wnieść dodatkowe informacje do ustalonych modeli klasycznych. Przykład: analiza predykcyjna awarii sprzętu (uczenie maszynowe) świetnie sprawdzi się z pewnego rodzaju analizą FMEA (klasyczna).
Z drugiej strony w „lekkich” domenach, takich jak analityka klientów, przewidywanie churn, spłaty kredytów, na pierwszy plan wyjdą algorytmy uczenia maszynowego. A w punktacji można np. łączyć klasykę z NLP przy podejmowaniu decyzji o wydaniu pożyczki na podstawie pakietu dokumentów (akurat ten sam DSS oparty na dokumentach).
Klasyczne algorytmy uczenia maszynowego
Powiedzmy, że mamy zadanie: kierownik sprzedaży wyrobów stalowych musi zrozumieć na etapie przyjmowania wniosku od klienta, jaka jest jakość produkt końcowy trafi do magazynu i zastosuje pewne działania kontrolne, jeśli jakość jest niższa niż wymagana.Zróbmy to bardzo prosto:
Krok 0. Ustal zmienną docelową (dobrze np. zawartość tlenku tytanu w gotowym produkcie)
Krok 1. Zdecyduj o danych (przesyłaj z SAP, Access i ogólnie z dowolnego miejsca, do którego możemy dotrzeć)
Krok 2. Zbieranie funkcji\generowanie nowych
Krok 3. Narysuj proces przepływu danych i uruchom go do produkcji
Krok 4. Wybierz i wytrenuj model, uruchom go na serwerze
Krok 5. Zdefiniuj znaczenie funkcji
Krok 6. Zdecyduj o wprowadzeniu nowych danych. Niech nasz manager wprowadzi je np. odręcznie.
Krok 7. Piszemy prosty interfejs webowy na kolanie, gdzie manager wprowadza wartościami ważnych funkcji z uchwytami, kręci się na serwerze z modelem, a przewidywana jakość produktu jest wypluwana w ten sam interfejs
Voila, IDSS na poziomie przedszkolnym jest gotowe, możesz z niego skorzystać.
Podobne "proste" algorytmy są również używane przez IBM w swoim Tivoli DSS, który pozwala określić stan swoich superkomputerów (przede wszystkim Watson): na podstawie logów wyświetlane są informacje o wydajności Watsona, dostępności zasobów, bilansie kosztów i zysków, potrzebach konserwacyjnych itp.
Spółka WĄTEK oferuje swoim klientom DSS800 do analizy pracy silników elektrycznych tej samej firmy ABB na linii papierowej.
fiński Wajsala, producent czujników dla fińskiego Ministerstwa Transportu, wykorzystuje IDSS do przewidywania, kiedy należy zastosować odladzanie na drogach, aby uniknąć wypadków.
Znowu fiński. Dane wstępne oferuje IDSS for HR, który pomaga podejmować decyzje o przydatności kandydata na dane stanowisko już na etapie wyboru CV.
Na lotnisku w Dubaju w terminalu cargo działa DSS, który określa podejrzany charakter ładunku. Pod maską algorytmy, oparte na dokumentach towarzyszących i danych wprowadzonych przez celników, wykrywają podejrzane ładunki: cechami są kraj pochodzenia, informacje na opakowaniu, szczegółowe informacje w polach deklaracji itp.
Tysiące!
Konwencjonalne sieci neuronowe
Oprócz prostej ML, Deep Learning doskonale pasuje do DSS.Kilka przykładów można znaleźć w kompleksie wojskowo-przemysłowym, np. w amerykańskim TACDSS (Tactical Air Combat Decision Support System). Tam neurony i algorytmy ewolucyjne wirują wewnątrz, pomagając w określeniu przyjaciela lub wroga, w ocenie prawdopodobieństwa trafienia salwy w danym momencie i innych zadaniach.
W nieco bardziej realnym świecie rozważmy ten przykład: w segmencie B2B trzeba ustalić, czy udzielić pożyczki organizacji na podstawie pakietu dokumentów. To w B2C operator zamęcza Cię pytaniami przez telefon, zapisuje wartości funkcji w swoim systemie i ogłasza decyzję algorytmu, w B2B jest to nieco bardziej skomplikowane.
IDSS można tam zbudować w następujący sposób: potencjalny pożyczkobiorca przynosi do urzędu wcześniej uzgodniony pakiet dokumentów (no lub wysyła skany e-mailem, z podpisami i pieczęciami, zgodnie z oczekiwaniami), dokumenty są wprowadzane do OCR, a następnie przekazywane do Algorytm NLP, który dalej dzieli słowa na cechy i przekazuje je NN. Klient proszony jest o napicie się kawy (najlepiej) lub tam właśnie została wydana karta i udanie się po lunch, w czasie którego wszystko zostanie obliczone i wyświetli zieloną lub czerwoną buźkę na ekranie dziewczyny operatora. Cóż, lub żółty, jeśli wydaje się w porządku, ale bóg informacji potrzebuje więcej informacji.
Podobne algorytmy stosuje się również w MSZ: wniosek wizowy + inne zaświadczenia są analizowane bezpośrednio w ambasadzie/konsulacie, po czym na ekranie pracownika wyświetla się jedna z 3 emotikonów: zielona (wydanie wizy), żółty (mam pytania), czerwony (wnioskodawca na liście przystanków). Jeśli kiedykolwiek otrzymałeś wizę do USA, to decyzja, którą wydaje Ci urzędnik konsularny, jest właśnie wynikiem algorytmu w połączeniu z przepisami, a nie jego osobistą subiektywną opinią o Tobie :)
W domenach ciężkich znane są również DSS oparte na neuronach, które określają miejsca akumulacji buforów na liniach produkcyjnych (patrz np. Tsadiras AK, Papadopoulos CT, O'Kelly MEJ (2013) System wspomagania decyzji oparty na sztucznej sieci neuronowej do rozwiązywania problemu alokacji buforów w niezawodnych liniach produkcyjnych. Comput Ind Eng 66(4):1150–1162), Min-Max Ogólne rozmyte sieci neuronowe (GFMMNN) dla klastrowania odbiorców wody ( Arsene CTC, Gabrys B, Al-Dabass D (2012) System wspomagania decyzji w systemach dystrybucji wody oparty na sieciach neuronowych i teorii grafów do wykrywania wycieków. Aplikacja Expert Syst 39(18): 13214–13224) inny.
Ogólnie warto zauważyć, że sieci NN najlepiej nadają się do podejmowania decyzji w warunkach niepewności, tj. warunki, w jakich żyje prawdziwy biznes. Algorytmy klastrowania również dobrze pasują.
Sieci bayesowskie
Czasami zdarza się, że nasze dane są niejednorodne pod względem rodzajów zdarzeń. Weźmy przykład z medycyny. Przyszedł do nas pacjent. Wiemy coś o nim z ankiety (płeć, wiek, waga, wzrost itp.) oraz wywiadu (na przykład przebyte zawały serca). Nazwijmy te dane statycznymi. A dowiadujemy się o nim czegoś w trakcie okresowych badań i leczenia (kilka razy dziennie mierzymy temperaturę, skład krwi itp.). Nazywamy to dynamiką danych. Oczywiste jest, że dobry DSS powinien być w stanie uwzględnić wszystkie te dane i wydać zalecenia w oparciu o kompletność informacji.Dane dynamiczne są aktualizowane w czasie, odpowiednio wzór modelu będzie wyglądał następująco: nauka-rozwiązanie-nauka, co generalnie jest podobne do pracy lekarza: z grubsza określ diagnozę, zalej lek, poszukaj reakcji. W związku z tym stale jesteśmy w stanie niepewności, czy leczenie zadziała, czy nie. A stan pacjenta zmienia się dynamicznie. Tych. musimy zbudować dynamiczny DSS, a także oparty na wiedzy.
W takich przypadkach bardzo pomogą nam Dynamic Bayesian Networks (DBN) - uogólnienie modeli opartych na filtrach Kalmana i ukrytych modelach Markowa.
Podzielmy dane o pacjencie na statyczne i dynamiczne.

Gdybyśmy budowali statyczną siatkę bayesowską, naszym zadaniem byłoby obliczenie następującego prawdopodobieństwa:
,Gdzie jest węzeł naszej siatki (w rzeczywistości wierzchołek wykresu), tj. wartość każdej zmiennej (płeć, wiek...), a C to przewidywana klasa (choroba).
Siatka statyczna wygląda tak:

Ale to nie lód. Stan pacjenta się zmienia, czas ucieka, trzeba zdecydować, jak go leczyć.
Po to jest DBS.
Najpierw w dniu przyjęcia pacjenta budujemy siatkę statyczną (jak na powyższym obrazku). Potem każdego dnia i budujemy grid w oparciu o dynamicznie zmieniające się dane:

W związku z tym model zagregowany przyjmie następującą postać:

W ten sposób obliczamy wynik według następującego wzoru:
Gdzie T- łączny czas hospitalizacji, n- liczba zmiennych na każdym z kroków DBS.
Konieczne jest wprowadzenie tego modelu do DSS w nieco inny sposób - raczej tutaj trzeba iść odwrotnie, najpierw naprawić ten model, a potem zbudować interfejs wokół. Czyli tak naprawdę zrobiliśmy twardy model, wewnątrz którego znajdują się elementy dynamiczne.
Teoria gry
Z kolei teoria gier jest znacznie lepiej dopasowana do IDSS, stworzonego do podejmowania strategicznych decyzji. Weźmy przykład.Załóżmy, że na rynku jest oligopol (mała liczba rywali), jest pewien lider, a to (niestety) nie jest naszą firmą. Musimy pomóc kierownictwu w podjęciu decyzji o ilościach naszych produktów: jeśli produkujemy produkty w dużych ilościach, a nasz rywal - czy pójdziemy na minus, czy nie? Dla uproszczenia weźmy szczególny przypadek oligopolu - duopolu (2 graczy). Kiedy myślisz, RandomForest jest tutaj lub CatBoost, sugeruję, abyś skorzystał z klasycznej równowagi Stackelberga. W tym modelu zachowanie firm jest opisane przez dynamiczną grę z kompletną doskonałą informacją, przy czym cechą gry jest obecność firmy wiodącej, która jako pierwsza ustala wielkość produkcji dóbr, a pozostałe firmy są kierując się nią w swoich obliczeniach.
Aby rozwiązać nasz problem, wystarczy obliczyć takie , które rozwiąże problem optymalizacji postaci:
Aby go rozwiązać (niespodzianka-niespodzianka!) wystarczy przyrównać pierwszą pochodną względem zera.
Jednocześnie dla takiego modelu wystarczy nam tylko poznać ofertę rynkową i koszt na produkt naszego konkurenta, a następnie zbudować model i porównać wynikowy Q z tym, który nasz zarząd chce wprowadzić na rynek. Zgadzam się, jest to nieco łatwiejsze i szybsze niż piłowanie NN.
Dla takich modeli i opartego na nich DSS odpowiedni jest również Excel. Oczywiście, jeśli dane wejściowe muszą zostać obliczone, to potrzebne jest coś bardziej skomplikowanego, ale niewiele. Ten sam Power BI może to obsłużyć.
Szukanie zwycięzcy w bitwie ML vs ToG nie ma sensu. Zbyt różne podejścia do rozwiązania problemu, z ich plusami i minusami.

Co dalej?
Z najnowocześniejszy Wygląda na to, że IDSS wymyśliło, co dalej?W niedawnym wywiadzie Judah Pearl, twórca tych samych sieci bayesowskich, przedstawił interesującą kwestię. Sformułując nieco,
„Wszyscy eksperci od uczenia maszynowego robią teraz, dopasowują krzywą do danych. Dopasowanie nie jest trywialne, skomplikowane i ponure, ale nadal pasuje”.(czytać)
Najprawdopodobniej, wangyu, za 10 lat przestaniemy kodować modele na sztywno, a zamiast tego zaczniemy uczyć komputerów wszędzie w stworzonych symulowanych środowiskach. Prawdopodobnie implementacja IDSS pójdzie tą ścieżką - ścieżką AI i innych skynetów i WAPR-ów.
Jeśli spojrzymy z bliższej perspektywy, to przyszłość IDSS leży w elastyczności decyzji. Żadna z proponowanych metod (modele klasyczne, uczenie maszynowe, DL, teoria gier) nie jest uniwersalna pod względem wydajności dla wszystkich zadań. Dobry DSS powinien łączyć wszystkie te narzędzia + RPA, podczas gdy różne moduły powinny być używane poniżej różne zadania i mieć różne interfejsy wyjściowe dla różnych użytkowników. Rodzaj koktajlu, zmieszany, ale nie wstrząśnięty.

Literatura
- Merkert, Mueller, Hubl, Ankieta zastosowania uczenia maszynowego w systemach wspomagania decyzji, Uniwersytet Hoffenheim 2015
- Tariq, Rafi,Inteligentne systemy wspomagania decyzji – ramy, Indie, 2011 r.
- Sanzhez i Marre, Gibert, Ewolucja systemów wspomagania decyzji, Uniwersytet w Katalonii, 2012
- Ltifi, Trabelsi, Ayed, Alimi, Dynamiczny system wspomagania decyzji oparty na sieciach bayesowskich, University of Sfax, National School of Engineers (ENIS), 2012
Systemy Wspomagania Decyzji(DSS) to systemy komputerowe, prawie zawsze interaktywne, zaprojektowane w celu wspomagania kierownika (lub przełożonego) w podejmowaniu decyzji. DSS zawierają zarówno dane, jak i modele, aby pomóc decydentom w rozwiązywaniu problemów, zwłaszcza tych, które są słabo sformalizowane. Dane są często pobierane z systemu przetwarzania zapytań online lub bazy danych. Model może być prostym typem „zysków i strat” do obliczania zysków przy pewnych założeniach lub złożonym typem modelu optymalizacyjnego do obliczania obciążenia każdej maszyny na hali produkcyjnej. DSS i wiele systemów omówionych w następnych rozdziałach nie zawsze jest uzasadnionych tradycyjnym podejściem do kosztów i korzyści; w przypadku tych systemów wiele korzyści jest niematerialnych, takich jak głębsze podejmowanie decyzji i lepsze zrozumienie danych.
Ryż. Rysunek 1.4 pokazuje, że system wspomagania decyzji wymaga trzech podstawowych elementów: modelu zarządzania, zarządzania danymi w celu gromadzenia i ręcznego przetwarzania danych oraz zarządzania dialogiem w celu ułatwienia użytkownikom dostępu do DSS. Użytkownik wchodzi w interakcję z DSS za pośrednictwem interfejsu użytkownika, wybierając konkretny model i zestaw danych do użycia, a następnie DSS przedstawia użytkownikowi wyniki za pośrednictwem tego samego interfejsu użytkownika. Model zarządzania i zarządzanie danymi działają w dużej mierze za kulisami i wahają się od stosunkowo prostego modelu ogólnego w arkuszu kalkulacyjnym do złożonego, złożonego modelu planowania opartego na programowaniu matematycznym.
Ryż. 1.4. Komponenty systemu wspomagania decyzji
Niezwykle popularnym rodzajem DSS jest generator sprawozdań finansowych. Za pomocą arkusza kalkulacyjnego, takiego jak Lotus 1-2-3 lub Microsoft Excel, tworzone są modele do przewidywania różnych elementów organizacji lub kondycja finansowa. Jako dane wykorzystywane są poprzednie sprawozdania finansowe organizacji. Pierwotny model zawiera różne założenia dotyczące przyszłych trendów w kategoriach wydatków i dochodów. Po rozważeniu wyników modelu bazowego menedżer przeprowadza serię badań „co jeśli”, zmieniając jedno lub więcej założeń w celu określenia ich wpływu na stan początkowy. Na przykład menedżer może zbadać wpływ na rentowność, jeśli sprzedaż nowych produktów rosła o 10% rocznie. Lub kierownik może zbadać wpływ większego niż oczekiwano wzrostu cen surowców, takiego jak 7% zamiast 4% rocznie. Ten rodzaj generatora sprawozdań finansowych jest prostym, ale potężnym DSS, który pomaga w podejmowaniu decyzji finansowych.
Przykładem systemu DSS, który umożliwia wprowadzenie w życie transakcji na danych, jest policyjny system budżetowania zasięgu stosowany przez miasta w Kalifornii. System ten pozwala funkcjonariuszowi policji zobaczyć mapę i wyświetlić dane geograficzne obszaru, pokazuje dzwonki policji, rodzaje połączeń i czasy połączeń. Interaktywne możliwości graficzne systemu umożliwiają funkcjonariuszowi manipulowanie mapą, strefą i danymi w celu szybkiego i łatwego sugerowania wariantów alternatywnych wyjść policji.
Innym przykładem DSS jest interaktywny system planowania ilościowego i produkcji w dużej firmie papierniczej. Ten system wykorzystuje szczegółowe poprzednie dane, modele predykcyjne i planowania do gry na komputerze ogólne wskaźniki firmy o różnych założeniach planistycznych. Większość firm naftowych opracowuje DSS, aby wspierać podejmowanie decyzji dotyczących inwestycji kapitałowych. System ten zawiera różne warunki finansowe i modele tworzenia planów na przyszłość, które można przedstawić w formie tabelarycznej lub graficznej.
Wszystkie podane przykłady DSS są określane jako konkretne DSS. Są to rzeczywiste aplikacje, które pomagają w procesie podejmowania decyzji. W przeciwieństwie do tego, generator systemu wspomagania decyzji to system, który zapewnia zestaw możliwości do szybkiego i łatwego budowania określonych DSS. DSS Generator to pakiet oprogramowania zaprojektowany do pracy na zasadzie częściowo komputerowej. W naszym przykładzie sprawozdania finansowego Microsoft Excel lub Lotus 1-2-3 można uznać za generatory DSS, podczas gdy modele Excel lub Lotus 1-2-3 do projektowania sprawozdań finansowych dla prywatnego oddziału firmy są specyficznymi DSS.
DSS omówiono bardziej szczegółowo w rozdz. 2.2.
DSS pojawił się głównie dzięki wysiłkom amerykańskich naukowców na przełomie lat 70. i 80., czemu sprzyjało w dużej mierze szerokie zastosowanie komputerów osobistych, standardowych pakietów oprogramowania aplikacyjnego, a także znaczne postępy w tworzeniu systemów sztucznej inteligencji (AI) .
Charakterystyczne cechy SPPR.
DSS charakteryzuje się następującymi charakterystycznymi cechami.
Orientacja na rozwiązywanie słabo ustrukturyzowanych (sformalizowanych) zadań, typowa głównie dla wyższych szczebli zarządzania;
Możliwość kombinacji tradycyjne metody dostęp i przetwarzanie danych komputerowych z możliwościami modeli matematycznych i opartych na nich metod rozwiązywania problemów;
Orientacja dla nieprofesjonalnego użytkownika końcowego komputera poprzez zastosowanie interaktywnego trybu działania;
Wysoka adaptacyjność, dająca możliwość dostosowania się do funkcji dostępnego sprzętu i oprogramowania oraz wymagań użytkownika.
Miejsce DSS wśród systemów informatycznych. Model informacyjny organizacji można traktować jako następujący model hierarchiczny, który obejmuje następujące trzy poziomy (patrz Rysunek 4.3):
Przetwarzanie danych,
Przetwarzanie danych,
Podejmować decyzje.
Ryż. 4.3. Hierarchia systemów informatycznych w firmie |
Na pierwszym najniższym poziomie znajdują się SEOD. W hierarchii decyzji zarządczych poziom ten odpowiada poziomowi kontroli zarządczej automatyzującej przepływ pracy w organizacji. Główne cechy SOED to:
Przetwarzanie danych na poziomie kontroli operacyjnej,
Sprawne przetwarzanie transakcji handlowych przeprowadzanych przez organizację,
Planowanie i optymalizacja wydajności komputera,
Integracja plików opisujących zadania pokrewne,
Przygotowywanie raportów dla kierownictwa.
Na drugim środkowym poziomie, odpowiadającym poziomowi kontroli zarządczej, nacisk kładzie się na procedury przetwarzania informacji realizowane przez MIS. Przetwarzanie to zwykle odnosi się do planowania działań w takich obszarach funkcjonalnych organizacji jak marketing, produkcja, finanse, księgowość, personel. Należy wziąć pod uwagę główne cechy IMS:
Przygotowywanie informacji przydatnych na poziomie średniego kierownictwa,
Strukturyzacja (uporządkowanie) przepływów informacji,
Integracja (kombinacja) danych otrzymanych z SEOD w obszarach funkcjonalnych biznesu (marketing IMS, produkcja MIS itp.),
Tworzenie systemu zapytań-odpowiedzi i raportowanie do kierownictwa (najczęściej z wykorzystaniem baz danych).
Na trzecim najwyższym poziomie zarządzania, odpowiadającym planowaniu strategicznemu, kształtują się najważniejsze decyzje organizacji. DSS stosowane na tym poziomie (jak jasno wynika z tego, że DSS można stosować na dowolnym poziomie zarządzania) mają następujące cechy:
Przygotowywanie rozwiązań dla wyższej kadry zarządzającej,
Zapewnienie wysokiej adaptacji do zmian i wysoka prędkość odpowiedzi na prośby użytkowników,
Zapewnienie pomocy w podejmowaniu decyzji poszczególnym menedżerom.
Zarządzanie danymi w środowisku SEDI odbywa się głównie w celu przetwarzania bieżących operacji biznesowych prowadzonych przez firmę. Stworzenie IMS wiązało się z pojawieniem się DBMS, który umożliwił organizowanie trybów zapytań, przetwarzania danych oraz tworzenie różnych raportów zarządczych. Jednak główną zaletą stworzenia DBMS było obniżenie kosztów bieżącego programowania związanego z obsługą baz danych. Należy podkreślić, że wymagania stawiane przez użytkownika takim systemom są stosunkowo niskie. Wymagania dotyczące DSS są znacznie poważniejsze. Dotyczy to rosnącego zapotrzebowania na wiarygodne dane, w tym o charakterze probabilistycznym, a także zaostrzenia ograniczeń czasowych dotyczących trybu zapytania oraz wykorzystania danych pochodzących ze źródeł nieskomputeryzowanych. Spełnienie tych wymagań zapewnia szybką wymianę danych pomiędzy bazami danych wchodzącymi w skład DSS a dużą bazą przechowującą informacje o działalności firmy.
SEOD i MIS umożliwiają więc zaspokojenie potrzeb informacyjnych użytkownika poprzez szybki dostęp do potrzebnych danych i otrzymywanie raportów (budowanych o różnym stopniu przetwarzania danych), które ułatwiają podejmowanie decyzji. W przypadku DSS bardziej słuszne jest mówienie o zdolności systemu do tworzenia wspólnie z użytkownikiem Nowa informacja(często w formie gotowych alternatyw) do podejmowania decyzji.
Należy zauważyć, że rozważane podejście do ustalenia miejsca DSS wśród SI może być nieco mylące dla czytelnika. Może się więc wydawać, że DSS może być stosowany tylko na najwyższych szczeblach władzy. W rzeczywistości mogą być wykorzystywane do wspomagania podejmowania decyzji na każdym poziomie zarządzania. Ponadto decyzje podejmowane na różnych szczeblach władzy często wymagają koordynacji. Dlatego ważną funkcją DSS jest koordynacja decydentów na różnych szczeblach administracji, jak również w ramach tego samego szczebla. I wreszcie, czytelnikowi może się wydawać, że pomoc w podejmowaniu decyzji jest jedyną rzeczą, jakiej kierownictwo wyższego szczebla może potrzebować od systemów informatycznych. Podejmowanie decyzji to jednak tylko jedna z funkcji menedżerów, w której pomocy otrzymują pomoc od systemów informatycznych.
Należy również zauważyć, że sam termin „systemy informacji zarządczej” jest używany w literaturze w szerokim i wąskim znaczeniu. W szerokim znaczeniu obejmuje wszelkie rodzaje rozważanych systemów komputerowych (SEOD, MIS, DSS itp.) wykorzystywanych w interesie menedżerów. W wąskim znaczeniu termin ten oznacza rodzaj SI, który generuje raporty zarządcze, tj. ISU.
Struktura DSS
Do tej pory nie poruszyliśmy struktury DSS, uznając ją za swego rodzaju „czarną skrzynkę”. Pierwszy pomysł dotyczący struktury DSS można wyciągnąć z rozważań na ryc. 4.4.
Oprócz użytkownika DSS zawiera trzy główne komponenty: podsystem do przetwarzania i przechowywania danych, podsystem do przechowywania i używania modeli oraz podsystem oprogramowania. Ten ostatni obejmuje system zarządzania bazą danych (DBMS), system zarządzania modelową bazą danych (BMS) oraz system zarządzania dialogiem użytkownika z komputerem (UDC).
podsystem danych. Podsystem przetwarzania i przechowywania danych charakteryzuje się wszystkimi znanymi zaletami budowania i użytkowania baz danych. Jednak korzystanie z baz danych w ramach DSS charakteryzuje się pewnymi cechami (por. rys. 4.5). Na przykład,
 Ryż. 4.4. Struktura DSS |
Bazy danych DSS posiadają znacznie większy zestaw źródeł danych, w tym źródła zewnętrzne, które są szczególnie ważne przy podejmowaniu decyzji na wyższych szczeblach zarządzania, a także źródła danych nieskomputeryzowanych. Kolejną cechą jest możliwość wstępnej „kompresji” danych pochodzących z wielu źródeł, poprzez ich wstępne przetwarzanie w ramach procedur agregacji i filtrowania.
Dane odgrywają ważną rolę w DSS. Mogą być wykorzystywane bezpośrednio przez użytkownika lub jako dane wyjściowe do obliczeń z wykorzystaniem modeli matematycznych.
Podsystem danych DSS otrzymuje część danych z systemu do operacji przetwarzania wykonywanych przez firmę. Jednak tylko w nielicznych przypadkach dane uzyskane na poziomie przetwarzania transakcji handlowych są przydatne dla DSS. Aby móc z nich korzystać, dane te muszą być wstępnie przetworzone. Są na to dwie możliwości. Pierwszym z nich jest wykorzystanie DBMS zawartego w DSS do przetwarzania danych o działalności firmy. Drugim jest wykonanie przetwarzania poza DSS poprzez utworzenie w tym celu specjalnej bazy danych. Oczywiste jest, że druga z tych opcji jest preferowana dla firm z dużą liczbą transakcji handlowych.
 ITUC. 4.5. Struktura podsystemu danych DSS |
Przetwarzane dane o działalności firmy tworzą pliki ekstrakcyjne, które są przechowywane poza DSS w celu poprawy niezawodności i szybkości dostępu. Idea stworzenia specjalnej bazy danych do przetwarzania transakcji firmy opiera się na celowości oddzielenia obszaru automatycznego elektronicznego przetwarzania danych od obszaru mniej wykwalifikowanych użytkowników końcowych. Ponadto użytkownicy końcowi DSS, którzy oczekują od systemu szybkiej reakcji na ich żądania, nieustannie rywalizowaliby o czas maszynowy z procesem przetwarzania transakcji. Dlatego wiele organizacji pracujących z DSS korzysta z oddzielnego komputera działającego w ramach centralnego systemu MIS do przetwarzania swoich transakcji biznesowych.
Oprócz danych dotyczących działalności firmy, do funkcjonowania DSS wymagane są inne dane wewnętrzne. Potrzebne są więc na przykład szacunki menedżerów zatrudnionych w obszarach marketingu, finansów, produkcji, danych o przemieszczeniach personelu, danych inżynieryjnych itp. Dane te muszą być gromadzone, wprowadzane i utrzymywane w odpowiednim czasie.
Istotne, zwłaszcza dla wspomagania decyzji na wyższych szczeblach zarządzania, są dane ze źródeł zewnętrznych. Wymagane dane zewnętrzne powinny obejmować dane dotyczące konkurentów, gospodarek krajowych i światowych. W przeciwieństwie do danych wewnętrznych, dane zewnętrzne często można kupić od organizacji specjalizujących się w zbieraniu danych.
Obecnie szeroko badana jest kwestia włączenia do BON innego źródła danych – dokumentów, które obejmują zapisy, pisma, umowy, zamówienia itp. Jeśli treść tych dokumentów zostanie zapisana w pamięci (na przykład na dysku wideo), a następnie przetworzona zgodnie z pewnymi kluczowymi cechami (dostawcy, konsumenci, daty, rodzaje usług itp.), DSS otrzyma nowe potężne źródło Informacja.
Podsystem danych, będący częścią DSS, powinien mieć następujące możliwości:
Kompilacja kombinacji danych uzyskanych z różnych źródeł poprzez zastosowanie procedur agregacji i filtrowania;
Szybkie dodanie lub wykluczenie jednego lub drugiego źródła danych;
Zbudowanie logicznej struktury danych z punktu widzenia użytkownika;
Wykorzystywanie i manipulowanie nieformalnymi danymi w celu eksperymentalnego testowania alternatyw roboczych użytkownika;
Zarządzanie danymi z wykorzystaniem szerokiego zakresu funkcji zarządzania zapewnianych przez DBMS;
Zapewnienie całkowitej niezależności logicznej bazy danych zawartej w podsystemie danych DSS od innych baz operacyjnych działających w firmie.
Podsystem modelowy. DSS, oprócz udostępniania danych, zapewnia użytkownikom dostęp do modeli decyzyjnych. Osiąga się to poprzez wprowadzenie odpowiednich modeli do SI i wykorzystanie w nim bazy danych jako mechanizmu integracji modeli i komunikacji między nimi (patrz rys. 4.6).
Powstały DSS połączy zalety SEOD i MIS w zakresie przetwarzania danych i generowania raportów zarządczych z zaletami badań operacyjnych i ekonometrii w zakresie matematycznego modelowania sytuacji i znalezienia rozwiązania.
Proces tworzenia modeli powinien być elastyczny. Powinien zawierać specjalny język modelowania, zestaw pojedynczych bloków oprogramowania i modułów realizujących poszczególne komponenty różnych modeli, a także zestaw funkcji sterujących.
Wykorzystanie modeli zapewnia zdolność DSS do prowadzenia analiz. Modele wykorzystujące matematyczną interpretację problemu za pomocą określonych algorytmów przyczyniają się do znalezienia informacji przydatnych do podejmowania właściwych decyzji. Na przykład model Programowanie liniowe umożliwia określenie najkorzystniejszej program produkcyjny produkcja kilku rodzajów produktów przy określonych ograniczeniach zasobów.
Wykorzystanie modeli w ramach systemów informatycznych rozpoczęło się od wykorzystania metod i metod statystycznych analiza finansowa, które zostały zaimplementowane przez polecenia konwencjonalnych języków algorytmicznych. Później powstały specjalne języki, które umożliwiają modelowanie sytuacji typu „a co jeśli?” lub „jak to zrobić?” Takie języki, stworzone specjalnie do budowania modeli, umożliwiają budowanie modeli określonego typu, które dostarczyć rozwiązanie z elastyczną zmianą zmiennych.
Obecnie istnieje wiele rodzajów modeli i sposobów ich klasyfikacji, na przykład ze względu na cel użycia, zakres możliwych zastosowań, sposób ewaluacji zmiennych itp.
Celem tworzenia modeli jest optymalizacja lub opis jakiegoś obiektu lub procesu. Modele optymalizacyjne związane są ze znalezieniem minimalnych lub maksymalnych punktów niektórych wskaźników. Na przykład menedżerowie często chcą wiedzieć, jakie ich działania prowadzą do maksymalizacji zysku (minimalizacja kosztów). Modele optymalizacyjne dostarczają takich informacji. Modele opisowe opisują zachowanie niektórych systemów i nie są przeznaczone do celów zarządzania (optymalizacji).
Chociaż większość systemów ma charakter stochastyczny (tj. ich stanu nie można przewidzieć z absolutną pewnością), większość modeli matematycznych budowana jest jako deterministyczna. Modele deterministyczne oceniają zmienne za pomocą jednej liczby (w przeciwieństwie do modeli stochastycznych, które oceniają zmienne z wieloma parametrami). Modele deterministyczne są bardziej popularne niż modele stochastyczne, ponieważ są tańsze i trudniejsze oraz łatwiejsze w budowie i użytkowaniu. Ponadto często z ich pomocą można uzyskać informacje wystarczające do pomocy decydentowi.
Z punktu widzenia zakresu możliwych zastosowań modele dzielą się na modele specjalistyczne, przeznaczone do pracy tylko z jednym systemem oraz modele uniwersalne, przeznaczone do pracy z kilkoma systemami. Pierwsze z nich są droższe, zwykle służą do opisu unikalnych systemów i są dokładniejsze niż drugie.
Podstawa modelu. Modele w DSS tworzą bazę modelową, na którą składają się modele strategiczne, taktyczne i operacyjne, a także zestaw bloków modelowych, modułów i procedur wykorzystywanych jako elementy do budowy modeli (por. rys. 4.6). Każdy typ modelu ma swoje unikalne cechy.
Modele strategiczne są wykorzystywane na najwyższych szczeblach zarządzania w celu ustalenia celów organizacji, ilości zasobów potrzebnych do ich osiągnięcia, a także polityki pozyskiwania i wykorzystywania tych zasobów. Mogą być również przydatne do wyboru opcji lokalizacji przedsiębiorstw, przewidywania polityki konkurencji i tak dalej. Modele strategiczne charakteryzują się dużym zasięgiem, wieloma zmiennymi oraz prezentacją danych w skompresowanej, zagregowanej formie. Często dane te opierają się na źródłach zewnętrznych i mogą być subiektywne. Horyzont planowania w modelach strategicznych jest zwykle mierzony w latach. Modele te są zazwyczaj deterministyczne, opisowe, wyspecjalizowane do zastosowania w jednej konkretnej firmie.
Modele taktyczne wykorzystywane są przez menedżerów średniego szczebla do przydzielania i kontrolowania wykorzystania dostępnych zasobów. Wśród możliwych obszarów ich wykorzystania należy wskazać: planowanie finansowe, planowanie wymagań dla pracowników, planowanie wzrostu sprzedaży, schematy zabudowy dla przedsiębiorstw. Modele te mają zwykle zastosowanie tylko do poszczególnych części firmy (na przykład do systemu produkcji i dystrybucji) i mogą również obejmować agregaty. Horyzont czasowy objęty modelami taktycznymi wynosi od jednego miesiąca do dwóch lat. W tym przypadku mogą być również wymagane dane ze źródeł zewnętrznych, ale główny nacisk we wdrażaniu tych modeli należy położyć na dane wewnętrzne firmy. Zazwyczaj modele taktyczne są realizowane jako deterministyczne, optymalizacyjne i uniwersalne.
Modele operacyjne są wykorzystywane na niższych szczeblach zarządzania, aby wspierać podejmowanie decyzji operacyjnych z horyzontem mierzonym w dniach i tygodniach. Możliwe zastosowania tych modeli to m.in. wprowadzenie kalkulacji należności i kredytów, kalendarza planowanie produkcji, zarządzanie zapasami itp. Modele operacyjne zazwyczaj wykorzystują do swoich obliczeń dane wewnątrzfirmowe. Zwykle są deterministyczne, optymalizujące i ogólne (tzn. mogą być używane przez różne organizacje).
Oprócz modeli strategicznych, taktycznych i operacyjnych baza modeli DSS zawiera zestaw bloków modelowych, modułów i procedur. Może to obejmować procedury programowania liniowego, analizę statystyczną szeregów czasowych, analizę regresji itp. - od najprostszych procedur po złożone pakiety aplikacji. Bloki modeli, moduły i procedury mogą być używane zarówno indywidualnie, niezależnie, aby pomóc użytkownikom DSS, jak i w złożonych, łącznie, do budowania i utrzymywania modeli.
System zarządzania interfejsem. Skuteczność i elastyczność DSS w rozwiązywaniu niektórych problemów w dużej mierze zależy od charakterystyki zastosowanego interfejsu. Interfejs zawiera system oprogramowania kontrola dialogu (CUD), komputer i sam użytkownik.
Język użytkownika to te czynności, które użytkownik wykonuje w stosunku do systemu, korzystając z możliwości klawiatury, elektronicznych ołówków piszących na ekranie, joysticka, myszy, poleceń głosowych itp. Najprostszą formą języka akcji jest tworzenie formularzy dokumentów wejściowych i wyjściowych. Po otrzymaniu formularza wejściowego (dokumentu) użytkownik wypełnia go niezbędnymi danymi i wprowadza do komputera. DSS przeprowadza niezbędną analizę i wydaje wyniki w postaci dokumentu wyjściowego o ustalonej formie.
Zwiększona znacznie dla Ostatnio popularność interfejsu wizualnego opracowanego przez amerykańską firmę „Apple Mackintosh”, który opiera się na wykorzystaniu specjalnego urządzenia „myszy”. Za pomocą tego urządzenia użytkownik wybiera prezentowane mu na ekranie przedmioty i czynności w postaci obrazów, realizując w ten sposób język czynności.
Sterowanie komputerem ludzkim głosem jest najprostszą, a przez to najbardziej pożądaną formą języka akcji. Nie został jeszcze wystarczająco rozwinięty i dlatego nie jest zbyt popularny w DSS. Istniejące rozwiązania wymagają od użytkownika poważnych ograniczeń (ograniczony zestaw słów i wyrażeń; specjalne urządzenie uwzględniające charakterystykę głosu użytkownika; sterowanie powinno mieć formę dyskretnych poleceń, a nie zwykłej, płynnej mowy ). Technologia tego podejścia jest intensywnie ulepszana, aw niedalekiej przyszłości możemy spodziewać się pojawienia się nowego zaawansowanego DSS wykorzystującego mowę wprowadzania informacji.
Język komunikatów to to, co użytkownik widzi na ekranie (znaki, grafika, kolor), dane odebrane przez drukarkę, wyjście audio itd. Przez długi czas jedyną implementacją języka komunikatów był drukowany lub wyświetlany raport (lub inny wymagany komunikat). Teraz dołączyła do niego nowa możliwość prezentacji danych wyjściowych - grafika komputerowa. Umożliwia tworzenie kolorowej grafiki w trzech wymiarach na ekranie i papierze. W DSS coraz popularniejsze staje się wykorzystanie grafiki komputerowej, która znacząco zwiększa widoczność i interpretowalność danych wyjściowych.
W ciągu ostatnich kilku lat pojawił się nowy kierunek rozwoju grafiki komputerowej - animacja. Animacja jest szczególnie skuteczna w interpretacji wyników DSS związanych z modelowaniem systemy fizyczne i przedmioty. I tak np. DSS zaprojektowany do obsługi klientów w banku za pomocą rysunkowych modeli może realistycznie wyświetlić różne opcje organizacji obsługi w zależności od przepływu odwiedzających, dopuszczalnej długości kolejki, liczby punktów obsługi itp.
W najbliższych latach należy się spodziewać użycia ludzkiego głosu jako języka komunikatów DSS. Jako możliwy przykład można wskazać wykorzystanie tej formy w pracy DSS w obszarze finansów, gdzie w procesie generowania zgłoszeń alarmowych głosowo wyjaśniane są przyczyny wyłączności danego stanowiska.
Wiedza użytkownika jest tym, co użytkownik musi wiedzieć podczas pracy z systemem. Obejmuje to nie tylko plan działania, który jest w głowie użytkownika, ale także podręczniki, instrukcje i dane referencyjne wydawane przez komputer, gdy polecenie jest o pomoc. Instrukcje i dane referencyjne wydawane przez system na żądanie użytkownika zwykle nie są standardowe, ale zależą od miejsca w kontekście rozwiązania problemu, w którym znajduje się użytkownik DSS. Innymi słowy, pomoc jest wyspecjalizowana w danej sytuacji.
Bardzo pomocne dla użytkownika DSS mogą być tak zwane pliki wsadowe zawierające zaprogramowane instrukcje dla systemu do wykonania standardowych procedur. Takie pliki są aktywowane przez naciśnięcie jednego klawisza i nie wymagają od użytkownika znajomości języka poleceń. Przykładem jest procedura porównywania planowanego i rzeczywistego stanu produkcji (wartości w magazynie, wielkość produkcji, wpływy gotówkowe itp.), które są stale wykonywane w ramach zautomatyzowanego stanowiska pracy.
W przypadku wyraźnego braku wiedzy użytkownika na dany obszar tematyczny i samą BON, te ostatnie mogą być wykorzystywane jako symulatory pod okiem doświadczonych użytkowników lub ekspertów w badanej dziedzinie.
Poprawa interfejsu DSS jest zdeterminowana postępem w rozwoju każdego z trzech wskazanych komponentów.
Ważną miarą skuteczności zastosowanego interfejsu jest wybrana forma dialogu pomiędzy użytkownikiem a systemem. Obecnie najczęstszymi formami dialogu są: tryb odpowiedzi na wyzwanie, tryb poleceń, tryb menu i tryb wypełniania pustymi polami w wyrażeniach dostarczanych przez komputer. Każda forma, w zależności od rodzaju zadania, charakterystyki użytkownika i podejmowanej decyzji, może mieć swoje zalety i wady.
Interfejs DSS powinien mieć następujące możliwości:
Manipulować różnymi formami dialogu, zmieniając je w procesie decyzyjnym według wyboru użytkownika;
Przesyłaj dane do systemu na różne sposoby;
Odbieraj dane z różnych urządzeń systemu w różnych formatach;
Elastycznie utrzymuj (na życzenie udzielaj pomocy, sugeruj) wiedzę użytkownika.
Wymagania operacyjne dla DSS z punktu widzenia użytkownika.
Pierwsze trzy z poniższych wymagań są związane z rodzajem problemu rozwiązywanego przez decydenta. Reszta jest związana z rodzajem udzielanej mu pomocy.
1. DSS powinno zapewniać pomoc w podejmowaniu decyzji i być szczególnie skuteczne w rozwiązywaniu nieustrukturyzowanych i słabo ustrukturyzowanych problemów. Dotyczy to zadań, w których wykorzystanie modeli SEOD, MIS i badań operacyjnych zwykle nie dawało rezultatów.
2. DSS powinien zapewniać pomoc w podejmowaniu decyzji przez menedżerów wszystkich szczebli, a także w koordynowaniu decyzji wymagających udziału kilku szczebli kierownictwa.
3. DSS powinien zapewniać pomoc w podejmowaniu decyzji zarówno indywidualnych, jak i zbiorowych. Odnosi się to do decyzji, w których odpowiedzialność jest podzielona między kilku menedżerów lub w ramach grupy pracowników.
4. DSS powinno zapewniać pomoc na wszystkich etapach procesu decyzyjnego. Jak zostanie pokazane poniżej, jeśli na etapach badania problemu i zbierania danych DSS udziela jedynie dodatkowej pomocy (główny wkład ma zastosowanie MIS), to na wszystkich kolejnych etapach (poza etapem decyzyjnym) ), pomoc zapewniana przez DSS jest dominująca.
5. DSS, pomagając w podejmowaniu różnych decyzji, nie może zależeć od żadnego z nich.
6. Korzystanie z DSS powinno być łatwe. Gwarantuje to wysoka adaptacyjność systemu w zależności od rodzaju zadań, specyfiki środowiska organizacyjnego i użytkownika oraz przyjazny interfejs.
Grupa DSS
Wszystko, co zostało powiedziane powyżej o DSS, dotyczyło przede wszystkim wsparcia indywidualnych decyzji. Jednak menedżer rzadko podejmuje decyzję sam. Zarządy, rady naukowo-techniczne, zespoły projektantów, komisje problemowe – to nie jest pełna lista przykładów kolektywnego podejścia do podejmowania decyzji. Group DSS (GDSS) to interaktywne systemy komputerowe przeznaczone do wspierania grup pracowników w rozwiązywaniu słabo ustrukturyzowanych problemów.
Grupowe podejmowanie decyzji jest bardziej złożone niż indywidualne, ponieważ wiąże się z koniecznością pogodzenia różnych indywidualnych punktów widzenia. Dlatego głównym zadaniem SSPPR jest usprawnienie komunikacji w zespole roboczym. Ulepszona komunikacja skutkuje oszczędnością czasu pracy, który można wykorzystać, aby głębiej zagłębić się w dany problem i opracować więcej możliwych alternatyw do jego rozwiązania. Ocena większej liczby alternatyw przyczynia się do wyboru bardziej świadomej decyzji.
Z jednej strony znaczenie podejmowania decyzji grupowych, chroniczne wady komunikacji grupowej (patrz Rozdział 2) i ograniczone możliwości radzenia sobie z nimi, z drugiej strony, doprowadziły do stworzenia specjalnej technologii informacyjnej wspierającej decyzje grupowe.
Duża część tej technologii jest wdrażana za pośrednictwem Office Automation Systems (CAO)1, usprawniając komunikację między pracownikami. SPSS może być wyspecjalizowany (przystosowany do rozwiązywania tylko jednego rodzaju problemu) lub uniwersalny (przeznaczony do rozwiązywania szerokiego zakresu problemów). Wiele SPSS zawiera wbudowany mechanizm oprogramowania, który zapobiega rozwojowi negatywnych trendów w komunikacji grupowej (pojawianie się sytuacji konfliktowych, myślenie grupowe itp.).
Struktura SPSS. SPSS obejmuje sprzęt i oprogramowanie, a także procedury i personel (patrz rys. 4.7).
 Ryż. 4.7. Struktura grupowego systemu wspomagania decyzji |
Komponenty te zapewniają członkom grupy komunikację i inne wsparcie podczas omawiania problemów. Podczas pracy z systemem członkowie zespołu mają stały dostęp do bazy danych, bazy modeli oraz różnorodnych aplikacji. Kierownik grupy jest odpowiedzialny za dobór procedur niezbędnych do funkcjonowania grupy. Kierownik grupy i jej członkowie mają możliwość nawiązania dialogu.
Pomoc techniczna. SPSS zwykle używa jednej z następujących konfiguracji sprzętowych:
1. Jedyny komputer. W takim przypadku wszyscy uczestnicy gromadzą się wokół jednego komputera i na zmianę odpowiadają na pytania pojawiające się na ekranie monitora, aż do otrzymania rozwiązania. Korzystanie z tej konfiguracji jest przydatne tylko do celów edukacyjnych.
2. Sieć komputerów lub terminali. Każdy uczestnik jest przy swoim komputerze lub terminalu, mając możliwość prowadzenia dialogu z centralnym procesorem systemu.
3. Pokój decyzyjny. Sercem tej konfiguracji GDSS jest aplikacja CAO1 zwana konferencją komputerową i opisana w rozdziale 4.4. W pokoju decyzyjnym znajduje się lokalna sieć komputerowa z serwerem, na którym działa menedżer systemu. Jest również wyposażony we wspólny ekran, który pozwala pokazać wszystkim członkom grupy niezbędne informacje (indywidualne i zagregowane).
Oprogramowanie. Oprogramowanie GSPPR zawiera bazę danych, bazę modeli i programów do specjalnych zastosowań. Zapewnia możliwość pracy indywidualnej i grupowej użytkowników, a także utrzymania grupowych procedur decyzyjnych. Tak więc w zakresie pracy grupowej oprogramowanie GPSPR pozwala:
Dokonać liczbowego i graficznego podsumowania propozycji i wyników głosowania członków grupy;
Oblicz wagi alternatyw decyzyjnych, dokonaj anonimowego zapisu otrzymanych propozycji, wybierz lidera grupy, buduj procedury budowania konsensusu, zapobiegaj rozwojowi negatywnych trendów w komunikacji grupowej;
Przesyłaj dane tekstowe i liczbowe między członkami grupy, między członkami grupy a menedżerem grupy, a także między członkami grupy a procesorem GPSS.
Personel. Ten komponent GDSS obejmuje wszystkich członków grupy oraz stewarda, który jest obecny na każdym spotkaniu grupy i jest odpowiedzialny za sprzęt systemu oraz zarządzanie zmianą procedur dyskusji.
Proszę. Procedury są niezbędnym elementem GDSS, dzięki któremu zapewniona jest celowość wymiany poglądów, obiektywizm osiągania konsensusu oraz efektywne wykorzystanie oprogramowania i sprzętu systemu.
Wsparcie zapewniane przez SPSS. W celu analizy pracy SDSS wyróżnimy trzy poziomy narzędzi wsparcia dostarczanych przez te systemy:
Poziom 1. Wsparcie komunikacyjne
Poziom 2. Wspomaganie decyzji
Poziom 3. Wsparcie dla reguł gry
Poziom 1. Wsparcie komunikacji. Na tym poziomie SPSS, korzystając z możliwości CAO i programów specjalnych, może zapewnić następujące rodzaje wsparcia:
Przesyłanie wiadomości pomiędzy członkami grupy za pomocą poczty e-mail;
Stworzenie wspólnego ekranu widocznego dla wszystkich członków grupy i dostępnego z każdego miejsca pracy;
Możliwość anonimowego wprowadzania pomysłów (sugestii) i ich anonimowej oceny (ranking);
Wydawanie na wspólnym ekranie (lub monitorze każdego miejsca pracy) wszystkich informacji wyjściowych będących wynikiem dyskusji (wstępna i końcowa lista propozycji, wyniki głosowania itp.);
Tworzenie porządku obrad do dyskusji.
Poziom 2. Wspomaganie decyzji. Na tym poziomie SPSS, wykorzystując narzędzia programowe do modelowania i analizy decyzji, może zapewnić następujące rodzaje wsparcia:
Planowanie i modelowanie finansowe;
Korzystanie z drzew decyzyjnych;
Wykorzystanie modeli probabilistycznych;
Korzystanie z modeli alokacji zasobów.
Poziom 3. Wsparcie dla zasad gry. Na tym poziomie SPSS wykorzystuje specjalne oprogramowanie do przestrzegania ustalonych zasad przeprowadzania procedur grupowych (np. ustalanie kolejności wystąpień i zasad głosowania, akceptowalność pytań w danej chwili itp.).
jeden) . Przed spotkaniem lider grupy spotyka się z facylitatorem grupy, aby zaplanować pracę grupy, wybrać oprogramowanie i ustalić agendę.
2). Praca grupy zaczyna się od tego, że jej lider proponuje grupie pytanie lub problem do rozwiązania.
3). Następnie uczestnicy wpisują swoje odpowiedzi z klawiatury, która jest dostępna dla wszystkich. Po zapoznaniu się ze wszystkimi zgłoszonymi propozycjami, zgłaszają do nich uwagi (pozytywne lub negatywne).
4) . Facylitator, korzystając z programu uogólniania propozycji, przeszukuje zgłoszone propozycje pod kątem wspólnych terminów, tematów i pomysłów i tworzy z nich kilka uogólnionych propozycji z komentarzami, które są przekazywane wszystkim uczestnikom.
5) . Prowadzący inicjuje dyskusję na temat zdań uogólnionych (werbalnych lub elektronicznych). Na tym etapie, za pomocą specjalnych programów, następuje uszeregowanie (priorytetyzacja) omawianych propozycji.
6). W przypadku pięciu lub dziesięciu najlepszych propozycji rozpoczyna się nowa dyskusja, która je udoskonala i dalej ocenia.
7). Proces (opracowanie propozycji, ich uogólnienie i uszeregowanie) powtarza się lub kończy ostatecznym głosowaniem. Ten etap wykorzystuje specjalny program o nazwie „komentarz końcowy”, który tworzy komentarz do wybranych zdań uogólnionych.
BUDOWA I WYKORZYSTANIE DSS DO PLANOWANIA FINANSOWEGO
Opisany przykład opiera się na prawdziwych wydarzeniach, które miały miejsce w jednym z zachodnich banków.
Pod koniec kolejnego roku obrotowego bank, widząc znaczny spadek zysków, poczuł się zagrożony. Analiza zaistniałej sytuacji wykraczała poza zakres zwykłej działalności zarządczej.
Mimo, że bank ten należał do czołówki, jako jeden z pierwszych wprowadził karty kredytowe i skomputeryzowany system księgowy, wdrażanie w nim polityki kredytowej nadal odbywało się ręcznie.
Postanowiono stworzyć nowy system komputerowy Planowanie finansowe, który wykonuje analizy i prognozy, a także tworzy raporty w oparciu o dane z istniejącego już w banku systemu do obsługi operacji księgowych. Jednocześnie analiza dotyczyła pokrycia dynamiki zmian głównych wskaźników oceniających relację aktywów własnych banku do środków pożyczonych. Prognozowanie miało być prowadzone dla dwóch stałych horyzontów: 12 miesięcy i 5 lat.
System planowania finansowego (FPS) został wykorzystany w trzech obszarach:
Na początku każdego miesiąca wydawano sprawozdanie z działalności banku za miesiąc poprzedni;
W każdym miesiącu - rozwiązywanie bieżących problemów specjalnych i opracowywanie planów strategicznych;
Na koniec każdego roku kalendarzowego - opracowanie rocznych dokumentów budżetowych.
Jak łatwo zauważyć, w przeciwieństwie do obliczeń księgowych, które istniały już w banku IS (który był scentralizowanym EDMS), nowo utworzony SFS jest DSS, który zachowuje takie standardowe funkcje tych systemów jak
Dostęp do danych w dowolnym momencie;
Wsparcie podejmowanych decyzji poprzez wydawanie okresowych raportów zarządczych;
Wykorzystanie matematycznych modeli prognostycznych do oceny alternatyw i strategii;
Zapewnienie możliwości pracy w trybie dialogu (możliwość zmiany celów i ograniczeń w przypadku zmiany warunków i okoliczności na rynkach finansowych).
Dane. Uzyskane dane co miesiąc są ewidencjonowane w bazach zawierających informacje retrospektywne za ostatnie trzy lata w cyklu miesięcznym i za siedem i pół roku w cyklu kwartalnym. Ponadto bazy danych zawierają otrzymane informacje prognostyczne na kolejne 12 okresów miesięcznych.
Raporty i analizy. Co miesiąc system planowania finansowego tworzy kompletny zestaw dokumentów finansowych, w tym bilans, rachunek zysków i strat oraz raporty z najważniejszych wydajność komercyjna. Uzyskane dane miesięczne są porównywane z wynikami prognozy, budżetem oraz podobnymi danymi uzyskanymi w roku poprzednim. Ponadto system wydaje okresowe raporty dotyczące szczególnie stresujących (krytycznych) aspektów działalności banku, np. raport dotyczący wskaźnika oprocentowania i wielkości płatności odsetkowych.
Prognozowanie. Wszystkie wymienione raporty mogą być wydawane przez system za każdy z kolejnych 12 miesięcy. Zmienne objaśniające dla tych raportów mogą być wprowadzane bezpośrednio przez użytkowników lub generowane automatycznie ze względów strategicznych. W razie potrzeby można tu wykorzystać modele optymalizacyjne znajdujące się w bazie modeli systemu. Prognoza jest „rolling”, stale obejmując kolejne 12 miesięcy, ze stałą ponowną oceną danych na początku każdego miesiąca.
Zalety. Wprowadzenie SFP spowodowało wzrost rentowności banku ze względu na następujące czynniki:
Zbudowanie mechanizmu zarządzania najważniejszymi wskaźnikami bilansu, w tym płynnością i stosunkiem kapitału własnego do kapitału obcego;
Stworzenie bazy do koordynacji procesu decyzyjnego na poziomie planowania strategicznego;
Stworzenie zdolności kadry zarządzającej wyższego szczebla do szybkiego reagowania na zmieniające się przepisy, warunki rynkowe i wewnątrzbankowe
okoliczności;
Obniżenie kosztów tworzenia okresowych raportów zarządczych
Pytania do samodzielnego zbadania
1. Opisz sytuację, która skłoniła kierownictwo banku do utworzenia SFP.
2. Jakie korzyści przyniosło wprowadzenie SFP?
3. Opisać elementy składowe SFP, uzasadniając do jakiego typu IS należy.
3). DSS posiada możliwość zarządzania dialogiem pomiędzy użytkownikiem a systemem, a także zarządzania danymi i modelami.
Federalna Państwowa Budżetowa Instytucja Edukacyjna Wyższego Szkolnictwa Zawodowego
„ROSYJSKA AKADEMIA GOSPODARKI NARODOWEJ
I USŁUGA PUBLICZNA
pod PREZYDENTEM FEDERACJI ROSYJSKIEJ"
Północno-Zachodni Instytut Zarządzania
Wydział: Administracja państwowa i gminna
Dział: Zarządzanie Ogólne i Logistyka
Kurs pracy
"Systemy Wspomagania Decyzji"
student III roku
Dzienne nauczanie
Fetiskin Iwan Juriewicz
Kierownik pracy
profesor nadzwyczajny, kandydat nauk filologicznych
Mysin Nikołaj Wasiliewicz
Petersburg 2015
Wstęp
Rozdział 1. Teoretyczne aspekty i koncepcje systemów wspomagania decyzji
1 Definicja systemu wspomagania decyzji, jego funkcje
2 Struktura systemów wspomagania decyzji
3 magazyny danych
4 technologie OLAP
5 Inteligentny analiza danych
6 Klasyfikacje systemów wspomagania decyzji
7 aplikacji
8 Rynek DSS
9 Ocena systemu wspomagania decyzji (DSS)
Rozdział 2 Praktyka wdrażania DSS na przykładzie oddziałów terenowych Banku Rosji”
1 Sformułowanie celów i zadań badania, charakterystyka badanego obiektu
2 Ogólny przegląd i opis stanowiska
2.1 Opracowanie DSS w zarządzaniu działalnością oddziałów terytorialnych Banku Rosji
2.2 Opis podsystemów funkcjonalnych
2.3 Opracowanie DSS na poziomie specyfikacji technicznych, który wdraża rozwiązania metodyczne i instrumentalne
3 Wnioski i wyniki stosowania niniejszego DSS
Wniosek
Bibliografia
Wstęp
Rozwijające się relacje rynkowe, decentralizacja zarządzania, szybkie starzenie się informacji wyznaczają wysokie wymagania współczesnemu liderowi. Wiedza i umiejętne posługiwanie się przepisami zarządczymi znacznie ułatwiają pracę kierownikowi, pomagają mu ustalać priorytety i usystematyzować pracę. Struktury organizacyjne stanowią podstawę, na której budowane są wszelkie działania zarządcze.
Organizacje tworzą struktury w celu zapewnienia koordynacji i kontroli działań swoich jednostek i pracowników. Struktury organizacji różnią się od siebie złożonością (tj. stopniem podziału działań na różne funkcje), sformalizowaniem (tj. stopniem, w jakim wykorzystywane są ustalone z góry zasady i procedury), stosunkiem centralizacji i decentralizacji (tj. , poziomy, na których rozwiązania zarządcze).
Relacje strukturalne w organizacjach są przedmiotem zainteresowania wielu badaczy i menedżerów. Aby skutecznie osiągać cele, konieczne jest zrozumienie struktury pracy, działów i jednostek funkcjonalnych. Organizacja pracy i ludzi w dużym stopniu wpływa na zachowanie pracowników. Z kolei relacje strukturalne i behawioralne pomagają wyznaczać cele organizacji, wpływają na postawy i zachowania pracowników. Podejście strukturalne jest stosowane w organizacjach, aby zapewnić podstawowe elementy działań i relacje między nimi. Obejmuje wykorzystanie podziału pracy, objęcia kontrolą, decentralizacji i departamentalizacji.
W kontekście dynamiki nowoczesnej produkcji i struktury społecznej zarządzanie musi być w stanie Ciągły rozwój, którego dziś nie da się osiągnąć bez zbadania dróg i możliwości tego rozwoju, bez wybrania alternatywnych kierunków. Badania zarządcze prowadzone są w codziennej działalności menedżerów i pracowników oraz w pracy wyspecjalizowanych grup analitycznych, laboratoriów, działów. Potrzeba badań nad systemami zarządzania jest podyktowana dość dużym zakresem problemów, z którymi boryka się wiele organizacji. Sukces tych organizacji zależy od prawidłowego rozwiązania tych problemów.
Struktura organizacyjna zarządzania jest jedną z kluczowych koncepcji zarządzania, ściśle związaną z celami, funkcjami, procesem zarządzania, pracą menedżerów i podziałem uprawnień między nimi. W ramach tej struktury odbywa się cały proces zarządzania (przepływ przepływów informacji i podejmowanie decyzji zarządczych), w którym uczestniczą menedżerowie wszystkich szczebli, kategorii i specjalizacji zawodowych. Strukturę można porównać ze szkieletem budowy systemu zarządzania, zbudowanym tak, aby wszystkie procesy w nim zachodzące były realizowane terminowo i z zachowaniem wysokiej jakości.
Różnice w strukturze organizacji, w cechach ich funkcjonowania pozostawiają bardzo znaczący ślad działalność zarządcza, aw niektórych przypadkach mają na to decydujący wpływ. Ponadto działania lidera, jego cechy psychologiczne zależą nie tylko od rodzaju struktury organizacyjnej, ale także od jego hierarchicznego miejsca w tej strukturze, co de facto sprawia, że temat tego kursu jest najistotniejszy.
Uzasadnione naukowo tworzenie struktur zarządzania organizacją jest pilnym zadaniem nowoczesna scena przystosowanie podmiotów gospodarczych do gospodarki rynkowej. W nowoczesnych warunkach konieczne jest szerokie stosowanie zasad i metod projektowania organizacji zarządzającej opartej na systematycznym podejściu.
CELEM TEJ PRACY NA KURSIE jest poznanie zasady hierarchii w strukturze zarządzania organizacją.
Aby osiągnąć ten cel, w pracy zdefiniowano następujące zadania:
badanie istoty i zasad budowy struktur organizacyjnych, ich klasyfikacji i etapów rozwoju historycznego;
badanie istoty i zasad budowy struktur organizacyjnych;
budowanie strategii zmian organizacyjnych.
METODY BADAWCZE: analityczne, graficzne.
Do napisania tej pracy wykorzystano prace naukowe i opracowania autorów krajowych i zagranicznych poświęcone zagadnieniom zarządzania procesowego, tworzenia systemów wspomagania decyzji zarządczych. W pracy wykorzystano materiały publikowane w prasie rosyjskiej i zagranicznej, a także prezentowane na specjalistycznych, profesjonalnych stronach internetowych.
Rozdział 1. Teoretyczne aspekty i koncepcje systemów wspomagania decyzji
1 Definicja systemu wspomagania decyzji, jego funkcje
Oczywiste jest, że podejmowane decyzje dotyczące strategii i taktyki rozwoju miasta muszą być dokładnie przemyślane i uzasadnione. Jest to szczególnie ważne w systemach społeczno-gospodarczych, gdyż podejmowane decyzje dotyczą żyjących ludzi, ich kondycji materialnej i duchowej. Jednak do tej pory podejmowanie decyzji przez burmistrza, administrację miasta, komisje opiera się na doświadczeniu i intuicji liderów. Ale systemy społeczno-gospodarcze są złożone, a ich zachowanie jest trudne do przewidzenia ze względu na obecność ogromnej liczby bezpośrednich i sprzężenie zwrotne często nieoczywiste na pierwszy rzut oka. Mózg człowieka nie jest w stanie poradzić sobie z zadaniem tego wymiaru, dlatego niezbędne jest zapewnienie informacji i wsparcia analitycznego w podejmowaniu decyzji. W ostatnich latach ukształtował się i jest aktywnie wykorzystywany nowy kierunek w dziedzinie automatyzacji pracy menedżerów - systemy wspomagania decyzji. Z powodzeniem wykorzystywane są w różnych branżach: telekomunikacji, finansach, handlu, przemyśle, medycynie i wielu innych.
Koncepcja systemów wspomagania decyzji (DSS) obejmuje szereg połączonych narzędzi wspólny cel- promowanie podejmowania racjonalnych i skutecznych decyzji zarządczych.
System wspomagania decyzji (DSS) to zautomatyzowany system komputerowy, którego celem jest pomoc osobom podejmującym decyzje w trudnych warunkach w pełnej i obiektywnej analizie aktywności podmiotu. Jest to interaktywny system wykorzystujący reguły decyzyjne i odpowiadające im modele z bazami danych, a także interaktywny proces symulacji komputerowej.
DSS powstał w wyniku połączenia systemów informacji zarządczej i systemów zarządzania bazami danych. DSS to systemy człowiek-maszyna, które umożliwiają decydentom wykorzystanie danych, wiedzy, obiektywnych i subiektywnych modeli do analizowania i rozwiązywania nieustrukturyzowanych i słabo sformalizowanych problemów.
Proces decyzyjny to otrzymanie i wybór najbardziej optymalnej alternatywy, z uwzględnieniem błędnej kalkulacji wszystkich konsekwencji. Wybierając alternatywy, należy wybrać tę, która najpełniej spełnia cel, ale jednocześnie trzeba brać pod uwagę dużą liczbę sprzecznych wymagań i tym samym oceniać wybrane rozwiązanie według wielu kryteriów.
System wspomagania decyzji jest przeznaczony do wspierania decyzji wielokryterialnych w złożonym środowisku informacyjnym. Jednocześnie wielokryterialność rozumiana jest jako fakt, że rezultaty podejmowanych decyzji są oceniane nie przez jeden, ale przez sumę wielu wskaźników (kryteriów) rozpatrywanych jednocześnie. Złożoność informacji determinowana jest koniecznością uwzględnienia dużej ilości danych, których przetwarzanie bez pomocy nowoczesnych technologii komputerowych jest praktycznie niemożliwe. W tych warunkach liczba możliwe rozwiązania, z reguły jest bardzo duży, a wybór najlepszego z nich „na oko”, bez kompleksowej analizy, może prowadzić do rażących błędów.
DSS umożliwia także usprawnienie pracy liderów biznesu i zwiększenie jej efektywności. Znacznie przyspieszają rozwiązywanie problemów w biznesie. DSS przyczynia się do nawiązania kontaktu międzyludzkiego. Na ich podstawie można przeprowadzić szkolenie i szkolenie personelu. Te systemy informatyczne pozwalają zwiększyć kontrolę nad działalnością organizacji. Obecność dobrze funkcjonującego DSS zapewnia ogromną przewagę nad konkurencyjnymi konstrukcjami. Dzięki propozycjom DSS otwierają się nowe podejścia do rozwiązywania codziennych i niestandardowych zadań.
DSS charakteryzuje się następującymi charakterystycznymi cechami:
· orientacja na rozwiązywanie słabo ustrukturyzowanych (sformalizowanych) zadań, typowych głównie dla wyższych szczebli zarządzania; · możliwość łączenia tradycyjnych metod dostępu i przetwarzania danych komputerowych z możliwościami modeli matematycznych i opartych na nich metod rozwiązywania problemów; · skupić się na nieprofesjonalnym użytkowniku końcowym komputera poprzez zastosowanie interaktywnego trybu działania; · wysoka adaptacyjność, zapewniająca możliwość dostosowania się do funkcji dostępnego sprzętu i oprogramowania oraz wymagań użytkownika. System wspomagania decyzji rozwiązuje dwa główne zadania: .wybór najlepsze rozwiązanie z zestawu możliwych (optymalizacja); 2.uporządkowanie możliwych rozwiązań według preferencji (ranking). Do analizy i opracowywania propozycji w DSS stosuje się różne metody. To może być: · wyszukiwanie informacji, · eksploracja danych, · szukaj wiedzy w bazy danych,
· Uzasadnienie w oparciu o przypadki · Modelowanie symulacyjne, · obliczenia ewolucyjne i algorytmy genetyczne, · sieci neuronowe, · analiza sytuacyjna, · modelowanie poznawcze itp. Niektóre z tych metod zostały opracowane w ramach sztucznej inteligencji. Jeśli praca DSS opiera się na metodach sztucznej inteligencji, to mówi się o intelektualnym DSS lub IDSS. Klasy systemów zbliżone do DSS to systemy ekspertowe i zautomatyzowane systemy sterowania. System pozwala rozwiązywać problemy zarządzania operacyjnego i strategicznego w oparciu o dane księgowe dotyczące działalności firmy. System wspomagania decyzji to zestaw narzędzi programowych do analizy danych, modelowania, prognozowania i podejmowania decyzji zarządczych, składający się z własnych opracowań korporacji oraz zakupionych produktów oprogramowania (Oracle, IBM, Cognos). Badania teoretyczne nad rozwojem pierwszych systemów wspomagania decyzji prowadzono w Carnegie Institute of Technology na przełomie lat 50. i 60. XX wieku. W latach 60. udało się połączyć teorię z praktyką przez specjalistów z Massachusetts Institute of Technology. W połowie i pod koniec lat 80. XX wieku zaczęły pojawiać się takie systemy jak EIS, GDSS, ODSS. W 1987 roku firma Texas Instruments opracowała system wyświetlania przypisania bramek dla United Airlines. To znacznie zmniejszyło straty z lotów i dostosowało zarządzanie różnymi lotniskami, od O International Airport Zając w Chicago, a kończąc na Stapleton w Denver w Kolorado. W latach 90. zakres możliwości DSS rozszerzył się dzięki wprowadzeniu hurtowni danych i narzędzi OLAP. Pojawienie się nowych technologii raportowania uczyniło DSS niezbędnym w zarządzaniu. 1.2 Struktura DSS Jeśli mówimy o strukturze DSS, istnieją cztery główne elementy: · Hurtownie danych informacyjnych. Hurtownia danych to bank danych o określonej strukturze, zawierający informacje o: proces produkcji firmy w kontekście historycznym. Głównym celem repozytorium jest zapewnienie szybkiej realizacji dowolnych zapytań analitycznych. (Więcej szczegółów na temat hurtowni danych omówiono w paragrafie 1.3 rozdziału 1.) · Wielowymiarowa baza danych i narzędzia analityczne OLAP (On-Line Analytical Processing) - usługa jest narzędziem do analizy dużych ilości danych w czasie rzeczywistym. (szczegóły w paragrafie 1.4 rozdziału 1) · Narzędzia do eksploracji danych. Za pomocą narzędzi do eksploracji danych możesz przeprowadzić głęboką eksplorację danych. (Więcej szczegółów w paragrafie 1.5 rozdziału 1.) DSS opiera się na zespole powiązanych ze sobą modeli z odpowiednim wsparciem informacyjnym dla systemów badawczych, eksperckich i inteligentnych, które obejmują doświadczenie w rozwiązywaniu problemów zarządczych oraz zapewniają udział zespołu ekspertów w procesie podejmowania racjonalnych decyzji. Rysunek 1 poniżej przedstawia schemat architektoniczno-technologiczny informacyjnego i analitycznego wspomagania decyzji: Rys.1 Schemat architektoniczno-technologiczny DSS Analityczne systemy DSS pozwalają na rozwiązanie trzech głównych zadań: .raportowanie, .analiza informacji w czasie rzeczywistym (OLAP), .eksploracja danych. 3 magazyny danych Oczywiste jest, że podejmowanie decyzji powinno opierać się na rzeczywistych danych dotyczących obiektu kontroli. Takie informacje są zwykle przechowywane w operacyjnych bazach danych systemów OLTP. Ale te dane operacyjne nie są odpowiednie do celów analizy, ponieważ zagregowane informacje są potrzebne głównie do analizy i podejmowania strategicznych decyzji. Dodatkowo na potrzeby analizy niezbędna jest możliwość szybkiej manipulacji informacją, prezentowania jej w różnych aspektach, wykonywania do niej różnych zapytań ad hoc, co jest trudne do zaimplementowania na danych operacyjnych ze względu na wydajność i złożoność technologiczną. Rozwiązaniem tego problemu jest stworzenie oddzielnej hurtowni danych (DW) zawierającej: informacje zagregowane w wygodny sposób. Celem budowy hurtowni danych jest integracja, aktualizacja i harmonizacja danych operacyjnych z heterogenicznych źródeł w celu utworzenia jednego spójnego obrazu obiektu sterowania jako całości. Jednocześnie koncepcja hurtowni danych opiera się na rozpoznaniu potrzeby oddzielenia zbiorów danych wykorzystywanych do przetwarzania transakcyjnego od zbiorów danych wykorzystywanych w systemach wspomagania decyzji. Taka separacja jest możliwa dzięki integracji szczegółowych danych wydzielonych w różnych systemach przetwarzania danych (DPS) i źródłach zewnętrznych w jeden magazyn, ich koordynacji i ewentualnie agregacji. Należy zwrócić uwagę na główne zalety hurtowni danych DSS: · Jedno źródło informacji: firma otrzymuje zweryfikowane jednolite środowisko informacyjne, na którym zbudowane zostaną wszystkie aplikacje referencyjne i analityczne w obszarze tematycznym, dla którego zbudowane jest repozytorium. Środowisko to będzie posiadało jednolity interfejs, ujednolicone struktury pamięci, wspólne katalogi i inne standardy korporacyjne, co ułatwi tworzenie i obsługę systemów analitycznych. · Również przy projektowaniu hurtowni danych informacji zwraca się szczególną uwagę na wiarygodność informacji, które trafiają do repozytorium. · Wydajność: Fizyczne struktury hurtowni danych są specjalnie zoptymalizowane do wykonywania całkowicie losowych wyborów, co pozwala na budowanie naprawdę szybkich systemów zapytań. · Szybkość rozwoju: specyficzna logiczna organizacja repozytorium oraz istniejące specjalistyczne oprogramowanie pozwalają na tworzenie systemów analitycznych przy minimalnych kosztach programowania. · Integracja: integracja danych z różnych źródeł jest już wykonana, dzięki czemu nie jest konieczne każdorazowe łączenie danych dla zapytań wymagających informacji z kilku źródeł. Integracja dotyczy nie tylko wspólnego fizycznego przechowywania danych, ale także ich merytorycznego, skoordynowanego powiązania; czyszczenie i wyrównanie podczas ich formowania; zgodność z funkcjami technologicznymi itp. · Historyczność i stabilność: Systemy OLTP działają na aktualnych danych, których okres stosowania i przechowywania zwykle nie przekracza wartości bieżącego okresu biznesowego (od sześciu miesięcy do roku), natomiast hurtownia danych jest przeznaczona do długoterminowe przechowywanie informacji przez 10-15 lat. Stabilność oznacza, że faktyczne informacje w hurtowni danych nie są aktualizowane ani usuwane, a jedynie dostosowywane w specjalny sposób do zmian atrybutów biznesowych. W ten sposób możliwe staje się przeprowadzenie historycznej analizy informacji. · Niezależność: przydział pamięci informacji znacznie zmniejsza obciążenie systemów OLTP od aplikacji analitycznych, dzięki czemu wydajność istniejących systemów nie ulega pogorszeniu, ale w praktyce następuje skrócenie czasu odpowiedzi i poprawa dostępności systemu. Hurtownia danych działa więc zgodnie z następującym scenariuszem. Zgodnie z daną regulacją zbiera dane z różnych źródeł – baz danych systemów przetwarzania online. Pamięć obsługuje chronologię: wraz z danymi bieżącymi przechowywane są dane historyczne ze wskazaniem czasu, do którego się odnoszą. W efekcie niezbędne dostępne dane o obiekcie kontrolnym są gromadzone w jednym miejscu, sprowadzane do jednego formatu, uzgadniane, aw niektórych przypadkach agregowane do minimalnego wymaganego poziomu uogólnienia. A w oparciu o hurtownię danych już teraz można sporządzać raporty do zarządzania, analizować dane z wykorzystaniem technologii OLAP oraz data mining (Data Mining). Usługa raportowania DSS pomaga organizacji radzić sobie z tworzeniem wszelkiego rodzaju raportów informacyjnych, certyfikatów, dokumentów, zestawień podsumowujących itp., zwłaszcza gdy liczba wydawanych raportów jest duża, a formy raportów często się zmieniają. Narzędzia DSS, automatyzując publikację raportów, umożliwiają konwersję ich przechowywania do postaci elektronicznej i dystrybucję w sieci korporacyjnej wśród pracowników firmy. Oprócz dużych korporacyjnych hurtowni danych szeroko stosowane są również Data Marty. Data mart to mała wyspecjalizowana pamięć masowa dla pewnego wąskiego obszaru tematycznego, skoncentrowana na przechowywaniu danych związanych z jednym tematem biznesowym. Projekt data mart wymaga mniej inwestycji i jest realizowany w bardzo krótkim czasie. Może istnieć kilka takich zbiorczych baz danych, na przykład zbiorcza baza danych o przychodach dla działu księgowości firmy i zbiorcza baza danych o klientach dla działu marketingu firmy. 1.4 Technologie OLAP Wchodząc w interakcję z systemem OLAP, użytkownik będzie mógł elastycznie przeglądać informacje, uzyskiwać dowolne wycinki danych oraz wykonywać operacje analityczne w zakresie uszczegółowienia, splotu, dystrybucji end-to-end, porównania w czasie. Cała praca z systemem OLAP odbywa się merytorycznie. Koncepcja przetwarzania analitycznego online (OLAP) opiera się na wielowymiarowej reprezentacji danych. Termin OLAP został wprowadzony przez EF Codda w 1993 roku. W swoim artykule rozważał mankamenty modelu relacyjnego, przede wszystkim brak możliwości „łączenia, przeglądania i analizowania danych w kategoriach wielowymiarowych, czyli w sposób najbardziej zrozumiały dla analityków korporacyjnych” oraz zdefiniowany Ogólne wymagania do systemów OLAP, które rozszerzają funkcjonalność relacyjnych DBMS i zawierają wielowymiarową analizę jako jedną ze swoich cech. Według Codda, wielowymiarowe spojrzenie pojęciowe jest najbardziej naturalnym spojrzeniem kadry zarządzającej na przedmiot zarządzania. Jest to perspektywa wielokrotna, składająca się z kilku niezależnych wymiarów, wzdłuż których można analizować określone zbiory danych. Analiza równoczesna na wielu wymiarach danych jest definiowana jako analiza wielowymiarowa. Każdy wymiar obejmuje kierunki konsolidacji danych, składające się z szeregu kolejnych poziomów uogólnienia, gdzie każdy wyższy poziom odpowiada większemu stopniowi agregacji danych dla odpowiedniego wymiaru. Tym samym wymiar Wykonawca może być określony przez kierunek konsolidacji, składający się z poziomów uogólnienia „przedsiębiorstwo – oddział – dział – pracownik”. Wymiar „Czas” może nawet obejmować dwa kierunki konsolidacji — „rok – kwartał – miesiąc – dzień” i „tydzień – dzień”, ponieważ czas liczony według miesiąca i tygodnia jest niekompatybilny. W takim przypadku staje się możliwym arbitralny wybór pożądanego poziomu szczegółowości informacji dla każdego z pomiarów. Operacja schodzenia (drążenia) odpowiada przechodzeniu z wyższych poziomów konsolidacji do niższych; wręcz przeciwnie, operacja podnoszenia (zwijania) oznacza przechodzenie z niższych poziomów na wyższe. 1.5 Eksploracja danych Największym zainteresowaniem DSS jest data mining, ponieważ pozwala na najpełniejszą i dogłębną analizę problemu, umożliwia wykrycie ukrytych relacji i podjęcie najbardziej rozsądnej decyzji. Obecny poziom rozwoju sprzętu i narzędzia programowe od pewnego czasu umożliwia prowadzenie baz danych informacji operacyjnych na różnych szczeblach administracji. W toku swojej działalności przedsiębiorstwa przemysłowe, korporacje, struktury resortowe, organy władza państwowa a samorządy zgromadziły duże ilości danych. Zawierają ogromny potencjał do wydobywania przydatnych informacji analitycznych, na podstawie których można identyfikować ukryte trendy, budować strategię rozwoju i znajdować nowe rozwiązania. Eksploracja danych, IAD (Data Mining) to proces wspomagania decyzji oparty na poszukiwaniu ukrytych wzorców (wzorców informacji) w danych. Jednocześnie zgromadzone informacje są automatycznie uogólniane na informacje, które można scharakteryzować jako wiedzę. Ogólnie proces IAD składa się z trzech etapów: .identyfikowanie wzorców; .wykorzystanie ujawnionych wzorców do przewidywania nieznanych wartości (modelowanie predykcyjne); .analiza wyjątków, mająca na celu identyfikację i interpretację anomalii w znalezionych wzorcach. Nowe technologie komputerowe tworzące IAD to systemy eksperckie i inteligentne, metody sztucznej inteligencji, bazy wiedzy, bazy danych, modelowanie komputerowe, sieci neuronowe, systemy rozmyte. Nowoczesne technologie IAD pozwala na tworzenie nowej wiedzy, odkrywanie ukrytych wzorców, przewidywanie przyszłego stanu systemów. Główną metodą modelowania rozwoju społeczno-gospodarczego miasta jest metoda symulacyjna, która pozwala na eksplorację systemu miejskiego z wykorzystaniem podejścia eksperymentalnego. Umożliwia to rozgrywanie na modelu różnych strategii rozwoju, porównywanie alternatyw, uwzględnienie wpływu wielu czynników, w tym z elementami niepewności. Model skonstruowany w tej pracy należy do tej klasy systemów. Na jego podstawie samorządy szczebla strategicznego i taktycznego uzyskują możliwość analizowania dynamiki rozwoju złożonego społeczno-gospodarczego systemu miejskiego, identyfikowania nieoczywistych na pierwszy rzut oka relacji, porównywania różnych alternatyw, analizowania anomalii i jak najlepszego rozsądną decyzję. Obiecujące jest wykorzystanie łączonych metod podejmowania decyzji w DSS w połączeniu z metodami sztucznej inteligencji i modelowaniem komputerowym, różnymi procedurami symulacyjnymi i optymalizacyjnymi, podejmowaniem decyzji w połączeniu z procedurami eksperckimi. 1.6 Klasyfikacje DSS Istnieją trzy rodzaje DSS oparte na interakcji z użytkownikiem: · bierne pomagają w podejmowaniu decyzji, ale nie mogą wysuwać konkretnej propozycji; · aktywni uczestnicy są bezpośrednio zaangażowani w opracowanie odpowiedniego rozwiązania; · kooperacyjne polegają na interakcji DSS z użytkownikiem. Propozycja zgłoszona przez system może zostać sfinalizowana, poprawiona, a następnie odesłana do systemu w celu weryfikacji. Następnie propozycja jest ponownie przedstawiana użytkownikowi i tak dalej, dopóki nie zatwierdzi decyzji. Zgodnie z metodą wsparcia istnieją: · DSS oparte na modelach, wykorzystują w swojej pracy dostęp do modeli statystycznych, finansowych lub innych; · DSS oparty na komunikacji wspiera pracę dwóch lub więcej użytkowników zaangażowanych we wspólne zadanie; · DSS oparte na danych mają dostęp do szeregów czasowych organizacji. Wykorzystują w swojej pracy nie tylko dane wewnętrzne, ale także zewnętrzne; · DSS zorientowany na dokumenty manipuluje nieustrukturyzowanymi informacjami zawartymi w różnych formatach elektronicznych; · DSS oparte na wiedzy zapewnia specjalistyczne, oparte na faktach rozwiązania problemów. Ze względu na obszar zastosowania wyróżniamy: · Ogólnosystemowe — pracują z dużymi systemami pamięci masowej i są używane przez wielu użytkowników. Zgodnie z architekturą i zasadą działania istnieją: · Funkcjonalne DSS. Są najprostsze pod względem architektonicznym. Są powszechne w organizacjach, które nie stawiają sobie celów globalnych i mają niski poziom rozwoju technologii informatycznych. Cechą charakterystyczną funkcjonalnego DSS jest analiza danych zawartych w plikach systemów operacyjnych. Zaletami takiego DSS są kompaktowość wynikająca z zastosowania jednej platformy oraz wydajność wynikająca z braku konieczności przeładowywania danych do wyspecjalizowanego systemu. Wśród mankamentów można wymienić: zawężenie zakresu problemów rozwiązywanych za pomocą systemu, spadek jakości danych ze względu na brak etapu ich czyszczenia, wzrost obciążenia system operacyjny z możliwością wypowiedzenia. · DSS przy użyciu niezależnych baz danych. Są używane w dużych organizacjach z kilkoma działami, w tym z działami informatyki. Każda konkretna data mart jest tworzona w celu rozwiązywania konkretnych problemów i jest skoncentrowana na określonej grupie użytkowników. To znacznie poprawia wydajność systemu. Implementacja takich struktur jest dość prosta. Spośród punktów ujemnych można zauważyć, że dane są wielokrotnie wprowadzane do różnych witryn sklepowych, dzięki czemu można je duplikować. Zwiększa to koszt przechowywania informacji i komplikuje procedurę ujednolicenia. Zapełnianie data martów jest dość trudne ze względu na konieczność korzystania z wielu źródeł. Nie ma jednego obrazu działalności organizacji, ze względu na brak ostatecznej konsolidacji danych. · DSS oparty na dwupoziomowej hurtowni danych. Stosuje się w duże firmy, którego dane są konsolidowane w pojedynczy system. Definicje i sposoby przetwarzania informacji w tym przypadku są ujednolicone. Aby zapewnić normalne działanie takiego DSS, wymagane jest przydzielenie wyspecjalizowanego zespołu, który będzie go obsługiwał. Taka architektura DSS jest pozbawiona mankamentów poprzedniej, ale nie ma możliwości strukturyzacji danych dla poszczególnych grup użytkowników, a także ograniczenia dostępu do informacji. Mogą wystąpić problemy z wydajnością systemu. · DSS oparty na trzypoziomowej hurtowni danych. Takie DSS korzystają z hurtowni danych, z których tworzone są data marty, wykorzystywane przez grupy użytkowników, którzy rozwiązują podobne problemy. W ten sposób zapewniony jest dostęp zarówno do określonych danych strukturalnych, jak i do jednej skonsolidowanej informacji. Zapełnianie hurtowni danych jest uproszczone dzięki wykorzystaniu zweryfikowanych i oczyszczonych danych z jednego źródła. Istnieje korporacyjny model danych. Takie DSS wyróżniają się gwarantowaną wydajnością. Istnieje jednak nadmiarowość danych, co prowadzi do wzrostu wymagań dotyczących pamięci masowej. Ponadto konieczne jest skoordynowanie takiej architektury z różnymi obszarami o potencjalnie różnych wymaganiach. W zależności od zawartości funkcjonalnej interfejsu systemu istnieją dwa główne typy DSS: EIS i DSS (Execution Information System) - systemy informacyjne do zarządzania przedsiębiorstwem. Systemy te skierowane są do nieprzygotowanych użytkowników, posiadają uproszczony interfejs, podstawowy zestaw oferowanych funkcji oraz stałe formy prezentacji informacji. Systemy EIS kreślą ogólny wizualny obraz bieżącego stanu wskaźników efektywności biznesowej firmy oraz trendów ich rozwoju, z możliwością pogłębienia przedmiotowych informacji do poziomu dużych obiektów firmy. Systemy EIS - prawdziwy zwrot, jaki widzi zarząd firmy z wprowadzenia technologii DSS (Desicion Support System) 7 - w pełni funkcjonalne systemy do analizy i badania danych, przeznaczone dla przeszkolonych użytkowników, którzy posiadają wiedzę zarówno w zakresie tematyki badań oraz w zakresie umiejętności obsługi komputera. Zazwyczaj do wdrożenia systemów DSS (o ile dane są dostępne) wystarczy zainstalować i skonfigurować specjalistyczne oprogramowanie od dostawców rozwiązań dla systemów OLAP i Data Mining. Taki podział systemów na dwa typy nie oznacza, że budowa DSS zawsze wiąże się z implementacją tylko jednego z tych typów. EIS i DSS mogą działać równolegle, udostępniając wspólne dane i/lub usługi, udostępniając swoją funkcjonalność zarówno wyższej kadrze zarządzającej, jak i działom analitycznym firm. 1.7 Aplikacje Telekomunikacja Firmy telekomunikacyjne wykorzystują DSS do przygotowania i podjęcia zestawu decyzji mających na celu zatrzymanie swoich klientów i zminimalizowanie ich odpływu do innych firm. DSS pozwala firmom efektywniej realizować swoje programy marketingowe, atrakcyjniej rozliczać swoje usługi. Analiza rekordów z charakterystyką połączeń pozwala zidentyfikować kategorie klientów o podobnych wzorcach zachowań w celu zróżnicowania podejścia do pozyskiwania klientów z określonej kategorii. Istnieją kategorie klientów, którzy stale zmieniają dostawców w odpowiedzi na określone kampanie reklamowe. DSS pozwala zidentyfikować najbardziej cechy charakterystyczne„stabilni” klienci, tj. klientów, którzy przez długi czas pozostają lojalni wobec jednej firmy, dzięki czemu można skoncentrować swoją politykę marketingową na utrzymaniu tej konkretnej kategorii klientów. Bankowość DSS służą do lepszego monitorowania różnych aspektów bankowości, takich jak obsługa kart kredytowych, pożyczek, inwestycji itp., co może znacznie poprawić wydajność pracy. Identyfikacja przypadków nadużyć, ocena ryzyka kredytowania, prognozowanie zmian w kliencie – zakres DSS i metody eksploracji danych. Klasyfikacja klientów, dobór grup klientów o podobnych potrzebach pozwala na ukierunkowaną politykę marketingową, dostarczanie atrakcyjniejszych zestawów usług określonej kategorii klientów. Ubezpieczenie Zestaw aplikacji DSS w branży ubezpieczeniowej można nazwać klasycznym – jest to identyfikacja potencjalnych przypadków nadużyć, analiza ryzyka, klasyfikacja klientów. Wykrycie pewnych stereotypów w roszczeniach ubezpieczeniowych, w przypadku dużych kwot, może w przyszłości zmniejszyć liczbę oszustw. Analiza cech charakterystycznych przypadków wypłat z tytułu zobowiązań ubezpieczeniowych, Firmy ubezpieczeniowe może zmniejszyć ich straty. Uzyskane dane doprowadzą m.in. do rewizji systemu rabatów dla klientów, których dotyczą zidentyfikowane cechy. Klasyfikacja klientów umożliwia identyfikację najbardziej dochodowych kategorii klientów w celu dokładniejszego ukierunkowania istniejącego zestawu usług i wprowadzenia nowych usług. Sprzedaż Firmy handlowe wykorzystują technologie DSS do rozwiązywania takich problemów jak planowanie zakupów i magazynowania, analiza wspólne zakupy, szukaj wzorców zachowań w czasie. Analiza danych dotyczących ilości zakupów i dostępności towaru w magazynie w określonym przedziale czasu pozwala zaplanować zakup towaru np. w odpowiedzi na sezonowe wahania popytu na towar. Często kupując produkt, kupujący nabywa wraz z nim inny produkt. Identyfikacja grup takich towarów pozwala np. na umieszczanie ich na sąsiednich półkach w celu zwiększenia prawdopodobieństwa ich wspólnego zakupu. Poszukiwanie wzorców zachowań w czasie daje odpowiedź na pytanie „Jeżeli dzisiaj kupujący kupił jeden produkt, to po jakim czasie kupi kolejny?”. Na przykład kupując aparat, klient prawdopodobnie kupi w najbliższej przyszłości usługi filmowe, wywoływania i drukowania. Medycyna Istnieje wiele systemów eksperckich do stawiania diagnoz medycznych. Zbudowane są głównie w oparciu o reguły opisujące kombinacje różnych objawów różnych chorób. Za pomocą takich zasad dowiadują się nie tylko, na co choruje pacjent, ale także jak go leczyć. Zasady pomagają w doborze leków, określeniu wskazań - przeciwwskazań, nawigowaniu procedurami leczenia, tworzeniu warunków do najskuteczniejszego leczenia, przewidywaniu wyników zaleconego przebiegu leczenia itp. Technologie Data Mining umożliwiają wykrywanie wzorców w danych medycznych stanowiących podstawę niniejszych zasad. Genetyka molekularna i inżynieria genetyczna Być może najpilniejszym i jednocześnie jasnym zadaniem odkrywania prawidłowości w danych eksperymentalnych jest genetyka molekularna i inżynieria genetyczna. Tutaj jest ona sformułowana jako definicja tzw. markerów, które rozumiane są jako kody genetyczne kontrolujące pewne cechy fenotypowe organizmu żywego. Takie kody mogą zawierać setki, tysiące lub więcej powiązanych elementów. Na rozwój badań genetycznych przeznaczane są duże środki. W ostatnim czasie obserwuje się szczególne zainteresowanie zastosowaniem metod Data Mining w tym obszarze. Wiadomo, że kilka dużych firm specjalizuje się w stosowaniu tych metod do odszyfrowywania genomów ludzi i roślin. Chemia stosowana Metody eksploracji danych są szeroko stosowane w chemii stosowanej (organicznej i nieorganicznej). Tutaj często pojawia się pytanie o wyjaśnienie cech budowy chemicznej niektórych związków, które decydują o ich właściwościach. Zadanie to jest szczególnie istotne w analizie złożonych związków chemicznych, których opis obejmuje setki i tysiące elementów strukturalnych i ich wiązań. 1.8 Rynek DSS Na rynku DSS firmy oferują następujące rodzaje usług tworzenia systemów wspomagania decyzji: · Realizacja projektów pilotażowych na systemach DSS w celu zademonstrowania kierownictwu Klienta potencjału wysokiej jakości aplikacji analitycznych. · Tworzenie wspólnie z Klientem w pełni funkcjonalnych systemów DSS, w tym hurtowni danych i narzędzi Business Intelligence. · Projektowanie architektury hurtowni danych, w tym struktur magazynowych i procesów zarządzania. · Tworzenie „marketów danych” dla wybranego obszaru tematycznego. · Instalacja i konfiguracja narzędzi OLAP i Business Intelligence; ich dostosowanie do wymagań Klienta. · Analiza narzędzi do analizy statystycznej i „eksploracji danych” w celu doboru oprogramowania do architektury i potrzeb Klienta. · Integracja systemów DSS z firmowymi intranetami Klienta, automatyzacja elektronicznej wymiany dokumentów analitycznych pomiędzy użytkownikami magazynu. · Rozwój Systemów Informacji Wykonawczej (EIS) dla wymaganej funkcjonalności. · Usługi integracji baz danych w jedno środowisko przechowywania informacji · Szkolenie specjalistów Klienta w zakresie technologii hurtowni danych i systemów analitycznych, a także pracy z niezbędnymi produktami oprogramowania. · Świadczenie usług doradczych dla Klienta na wszystkich etapach projektowania i eksploatacji hurtowni danych oraz systemów analitycznych. · Kompleksowe projekty budowy/modernizacji infrastruktury obliczeniowej zapewniającej funkcjonowanie DSS: rozwiązania o dowolnej skali, od systemów lokalnych po systemy o skali przedsiębiorstwa/koncernu/branży. 1.9 Ocena systemu wspomagania decyzji (DMSS) Kryteria oceny DSS. System musi efektywnie zarządzać dochodem i ryzykiem w każdych warunkach rynkowych, generując skuteczne sygnały wejścia i wyjścia z rynku. Jednocześnie częstotliwość transakcji powinna być umiarkowana, biorąc pod uwagę koszty transakcji, prowizje, straty na spreadzie itp. Złożoność konstrukcji nie powinna onieśmielać. Większość z tych, którzy odrzucają metody numeryczne na rzecz swojej „intuicji”, kończy z wynikami poniżej średniej. Naturalnie ważną cechą w ocenie systemu jest całkowity (końcowy) zysk. Przy wysokich kosztach operacyjnych ważna staje się taka cecha, jak zysk na operację. Trafność decyzji (w procentach), liczona jako stosunek liczby operacji dochodowych do liczby operacji ogółem, jest popularną cechą wielu traderów, choć jej znaczenie jest przeceniane. Faktem jest, że wiele sprawnych systemów częściej podejmuje błędne decyzje niż prawidłowe, podczas gdy wiele nierentownych (lub prawie nierentownych) systemów częściej podejmuje prawidłowe decyzje. Ważną cechą pomiaru ryzyka stosowanych przez system strategii jest maksymalna strata środków własnych. Systemy podlegające okresowym dużym stratom nie mogą być uznane za nadające się do użytku, nawet jeśli ostatecznie dają wystarczający zysk netto. Jednocześnie maksymalne straty oznaczają nie tylko największą kwotę strat z ciągu nierentownych operacji, ale maksymalny spadek kapitału w analizowanym okresie. Podczas takiego spadku sekwencja przegranych transakcji może zostać przerwana przez pojedyncze zyskowne transakcje, które nie są w stanie zmienić ogólnej nierentowności okresu nieefektywności systemu. Główna cecha efektywności systemu jest obliczana jako stosunek całkowitego zysku do wysokości strat kapitałowych w okresie maksymalnej niesprawności systemu i jest zwykle nazywana wskaźnikiem zwrotu/ryzyka. Istnieje również wiele innych ocen skuteczności systemu, czasem dość skomplikowanych, wymagających dużej ilości obliczeń statystycznych, ale w większości przypadków powyższe proste cechy są wystarczające. Należy zauważyć, że przy ocenie systemu można skorzystać z kryteriów rekomendowanych przez teoria klasyczna zarządzanie portfelem. Optymalizacja systemu polega na znalezieniu najlepszej formuły dla wskaźnika - najlepszej pod względem uzyskania maksymalnego i/lub najbardziej stabilnego zysku z danych zbieranych przez długi okres czasu. Ta optymalizacja jest wewnętrznie sprzeczna. Jego krytycy od razu zwrócą uwagę, że przyszłe ceny mogą zachowywać się inaczej niż w przeszłości. Zwolennicy takiej optymalizacji muszą być przekonani o istnieniu pewnych wzorców, stabilności zachowań cenowych, które się nie zmieniają lub nieznacznie zmieniają w czasie. Aby sprawdzić skuteczność tego, że reguły stosowane w analizie technicznej dają w przyszłości stabilny zysk, będąc same w sobie wyliczane na podstawie danych z przeszłości, stosuje się następującą prostą metodę testowania (tzw. ślepe modelowanie). Najpierw reguła decyzyjna jest optymalizowana na danych z przeszłości, a następnie jest testowana na danych późniejszych (ostatnich). W ten sposób możesz określić, jak dobrze możesz ogólnie przewidzieć przyszłość na podstawie danych z przeszłości przy użyciu danej reguły. Jeśli wskaźnik o optymalnych parametrach dobrze radzi sobie na nowszych danych, można mieć nadzieję, że będzie dobrze działał w przyszłości. Przy ponownej ocenie parametrów systemu należy przejść do: nowy system tylko wtedy, gdy uzyskana „poprawa” jest statystycznie istotna. Robert Pelletier zaleca ograniczenie liczby parametrów przy konstruowaniu reguł decyzyjnych, ponieważ ich zwiększenie zwiększa liczbę stopni swobody systemu. Ponadto mogą istnieć między nimi powiązania, tzn. mogą się one okazać statystycznie zależne, co zwykle widać po ich współczynniku korelacji krzyżowej. Pelletier uważa, że dobry system powinien zawierać nie więcej niż 2-5 parametrów. Próba do sprawdzenia wskaźnika powinna być na tyle duża, aby dla wybranego okresu było co najmniej 30 sygnałów. W takim przypadku okres powinien zawierać całkowitą liczbę pełnych długich (niskich częstotliwości) cykli w celu ograniczenia wpływu błędów systematycznych w kierunku sprzedaży lub zakupów. A więc np. dla znanego 4-letniego cyklu giełdowego, analizę należy przeprowadzić na danych z co najmniej 8-letniego okresu. dane intelektualne banku organizacyjnego Rozdział 2 1 Sformułowanie celów i zadań badania, charakterystyka badanego obiektu W tej chwili Bank centralny Federacja Rosyjska(zwany dalej Bankiem Rosji) jest kluczowym regulatorem rosyjskiego systemu bankowego i pod wieloma względami jest gwarantem jego stabilności i stabilności gospodarczej. System Banku Rosji ma kompleks struktura organizacyjna- biuro centralne (zwane dalej CA), biura terenowe (zwane dalej TU) i zatrudnia ponad 80 tys. pracowników. Z kolei instytucje terytorialne podporządkowują sobie sieć centrów rozliczeń gotówkowych i innych jednostek zapewniających działalność TC.Obecność złożonej struktury organizacyjnej determinuje złożoność systemu zarządzania Banku Rosji, który obejmuje dwa poziomy - TC i CA. Obecnie dla Banku Rosji istotne są następujące główne zadania: ogólna redukcja kosztów, standaryzacja działalności instytucji terytorialnych oraz doskonalenie systemu zarządzania instytucjami terytorialnymi. Za główne narzędzie realizacji tych zadań uważa się procesowe podejście do zarządzania, którego realizację rozpoczęto w Banku Rosji w 2002 roku. Podejście procesowe to dominujące podejście do budowania elastycznego i wydajnego systemu zarządzania, które w ciągu ostatnich 10-15 lat upowszechniło się na świecie. Podejście procesowe zakłada jasne sformułowanie celów i strategii działania, opis działania w postaci zestawu powiązanych ze sobą procesów, które mają określone rezultaty na wyjściu, jasny podział odpowiedzialności pomiędzy wszystkich uczestników procesów. jak pokazuje światowa praktyka, skuteczne stosowanie podejścia procesowego jest w dużej mierze zdeterminowane obecnością systemu informacyjno-informatycznego, który generuje i dostarcza informacje niezbędne do podejmowania decyzji. Za pomocą takiego systemu, na poziomie specyfikacji technicznych Banku Rosji, można by opisywać i kontrolować realizację procesów, oszacować ich koszt, obliczyć rzeczywiste obciążenie, przeprowadzić rozsądną ocenę efektywności procesów, pracowników, działów itp. Na poziomie CA Banku Rosji system umożliwiłby porównywanie specyfikacji technicznych dla różnych wskaźników zgromadzonych w trakcie pracy, standaryzację specyfikacji technicznych, opisywanie standardów procesowych, powielanie ich w specyfikacjach technicznych i rozwiązywanie szeregu innych zadań. Wszystko to przesądza o aktualności tematu tego rozdziału, poświęconego rozwojowi metodologicznych, matematycznych i programowo-instrumentalnych podejść do tworzenia systemu wspomagania decyzji w zakresie zarządzania działalnością instytucji terytorialnych Banku Rosji z siedzibą na podejściu procesowym (zwanym dalej Systemem, DSS „Zarządzanie Procesami”). Celem niniejszej pracy jest opracowanie kompleksowego wsparcia metodologicznego, matematycznego, informacyjnego, programowego i instrumentalnego systemu wspomagania decyzji w zadaniach zarządzania działalnością instytucji terytorialnych Banku Rosji, w tym poziomu specyfikacji technicznych i poziomu centralne biuro. 2 Ogólny przegląd i opis stanowiska 2.1 Rozwój nowy koncept DSS w zarządzaniu działalnością oddziałów terytorialnych Banku Rosji Przeanalizowano specyfikę Banku Rosji polegającą na występowaniu złożonej struktury organizacyjnej, pionowego dwupoziomowego systemu zarządzania instytucjami terytorialnymi, jasnej regulacji działalności opartej na szeroko zakrojonych ramach regulacyjnych, złożoności dokumentu zarządzanie, funkcje zarządzania finansami, wymagania dotyczące informatyzacji i bezpieczeństwa. bezpieczeństwo informacji. W rezultacie stwierdzono, że istniejące produkty nie nadają się w pełni do rozwiązywania problemów związanych z zarządzaniem oddziałami terytorialnymi Banku Rosji. Studium specyfiki Banku Rosji i analiza głównych zadań w zarządzaniu działalnością instytucji technicznych pozwoliły na sformułowanie następujących zasad koncepcyjnych konstrukcji DSS: ) Struktura dwupoziomowa. Opracowany DSS powinien funkcjonować na dwóch poziomach – TU (regionalnym) i CA (federalnym). Na poziomie regionalnym DSS wspiera zarządzanie działaniami specyfikacji technicznych w oparciu o podejście procesowe; na poziomie federalnym zbierane są informacje o działaniach ze wszystkich specyfikacji technicznych, scentralizowane przechowywanie i analiza tych informacji, klasyfikacja specyfikacji technicznych, oraz tworzenie standardów; ) Zarządzanie pełnym cyklem oparte na podejściu procesowym. Dla efektywnego i ciągłego doskonalenia działań, ważną cechą DSS jest zapewnienie pełnego cyklu zarządzania opartego na podejściu procesowym, które obejmuje iteracyjne wykonywanie procedur opisujących procesy, monitorowanie i kontrolowanie wykonania, analizowanie procesów i reengineering. Biorąc pod uwagę dwupoziomową strukturę systemu, cykl sterowania przedstawiono w postaci (rys. 2): Ryż. 2. Cykl wsparcia zarządzania w DSS )Integracja podejść i technologii. W celu najefektywniejszego rozwiązywania problemów doskonalenia działań specyfikacji technicznych w tworzonym DSS konieczna jest integracja podejść i technologii zarządzania procesami biznesowymi (BPMS), zarządzania wydajnością (CPM) oraz business intelligence (BI). Podejścia te powinny być realizowane w oparciu o zunifikowane zasady architektoniczne i funkcjonować w ramach zunifikowanej infrastruktury informacyjnej, programowej i technologicznej; )Wsparcie norm jest niezbędne do rozwiązania problemów standaryzacji działalności PT. Na poziomie federalnym - opracowywanie, debugowanie, analiza standardów procesów itp.; na poziomie regionalnym - „narzucanie” standardów na istniejące procesy; )Integracja procesów w hurtowni danych. Systemy klasy BPMS są transakcyjne i nie wymagają hurtowni danych. W Banku Rosji wymagane jest nie tylko zorganizowanie zarządzania procesami, ale także zapewnienie ich kompleksowej analizy - dynamicznej, porównawczej, strukturalnej itp. Dlatego informacje o działaniach powinny być gromadzone w hurtowniach danych każdej instytucji technicznej, części dane zostaną przekazane na poziom federalny (do scentralizowanego repozytorium); )Opracowanie bazy metodologicznej analizy. Dla pełniejszego i bardziej efektywnego rozwiązania problemów analizy informacji o działaniach specyfikacji technicznych konieczne jest opracowanie bazy metodologicznej i instrumentalnej w następujących obszarach: kalkulacja kosztów procesów, ocena czasu trwania procesów, analiza struktury organizacyjnej, zarządzanie wydajnością; )Interakcja z TPK. DSS powinien współpracować ze standardowymi systemami oprogramowania (TPC) działającymi w instytucjach terytorialnych. Interakcja jest zorganizowana w celu: uzyskania danych wstępnych (np. danych o kosztach specyfikacji technicznych); uzyskiwanie aktualnych informacji regulacyjnych i referencyjnych; pozyskiwanie danych o realizacji procesów. Uwzględniając te zasady, opracowano koncepcyjny model systemu, obejmujący federalny i regionalny szczebel władzy (rys. 3): Ryż. 3. Model koncepcyjny DSS w zarządzaniu działalnością oddziałów terytorialnych Banku Rosji” Przedstawiony model koncepcyjny najpełniej odpowiada rozwiązaniu zadań zarządczych Banku Rosji i obejmuje następujące elementy: · Systemy na poziomie regionalnym (w każdej instytucji terytorialnej). DSS na poziomie regionalnym jest replikowalny i zapewnia funkcjonalność wspólną dla wszystkich specyfikacji technicznych. Informacje o działaniach TS gromadzone są w hurtowni danych, nad którą działają analityczne narzędzia BI. · System na poziomie federalnym (w biurze centralnym). DSS na poziomie federalnym to integrujący komponent, który obejmuje scentralizowane przechowywanie i przetwarzanie informacji o działaniach wszystkich specyfikacji technicznych i funkcji, które różnią się od systemu na poziomie regionalnym. System na poziomie federalnym generuje dane (standardy procesów, przepisy itp.), które są replikowane w DSS na poziomie regionalnym. · Zewnętrzne źródła informacji dostarczają głównie danych DSS na poziomie regionalnym, obejmują różne systemy oprogramowania działające w instytucjach terytorialnych. Źródła zewnętrzne można uznać za zewnętrzne komponenty DSS. Ponieważ system na poziomie federalnym w dużej mierze opiera się na danych przesyłanych z systemów na poziomie regionalnym, konieczne jest najpierw opracowanie informacyjnego, matematycznego i instrumentalnego wsparcia systemu na poziomie regionalnym jako podstawy integralnego DSS Banku Rosji. Jednocześnie należy zauważyć, że wypracowane metody i narzędzia zostaną wykorzystane przy budowie systemu na poziomie federalnym. W toku badań opracowano strukturę BON na poziomie regionalnym (ryc. 4), z uwzględnieniem skali specyfikacji technicznych, różnorodności realizowanych funkcji i procesów, czynników utrwalonej praktyki zarządzania oraz cechy obecnej automatyzacji. Ryż. 4. Struktura DSS na poziomie regionalnym Banku Rosji” 2.2.2 Opis podsystemów funkcjonalnych W skład systemu wchodzą podsystemy funkcjonalne zapewniające interfejsy użytkownika i realizujące funkcje biznesowe oraz podsystemy technologiczne zapewniające działanie podsystemów funkcjonalnych w oparciu o ujednolicone mechanizmy zarządzania danymi i scentralizowane metadane. Wszystkie podsystemy działają pod kontrolą podsystemu administracji i bezpieczeństwa informacji, co zapewnia odpowiedni poziom ochrony danych przed nieuprawnionym dostępem zgodnie z wymogami Banku Rosji. W toku badań, biorąc pod uwagę specyfikę Banku Rosji, opracowano i uzasadniono wymagania dotyczące wsparcia informacyjnego i instrumentalnego podsystemów funkcjonalnych. Podsystem opisu procesów jest przeznaczony do sformalizowanego opisu działań w postaci zestawu powiązanych ze sobą procesów, z uwzględnieniem cech Banku Rosji. Do modelowania procesów w systemie wykorzystano standardy IDEF0 i IDEF3, uzupełnione o szereg dodatkowych struktur: operacje sterujące, przejścia powrotne, powiązania z innymi procesami, procesy pomocnicze, punkty początkowe i końcowe procesu. Przy tworzeniu modelu informacyjnego do opisu procesów SPW wzięto pod uwagę specyfikę Banku Rosji oraz wymagania norm, a także następujące zasady: · Obsługa wersjonowania implikuje zachowanie chronologii wszystkich zmian w opisie procesu (zmiany obiektów są rejestrowane jako wersje posortowane według daty). Dzięki temu możliwe jest uzyskanie modelu działania specyfikacji technicznych na dowolny termin; · Wsparcie dla modelowania zmian zapewnia utrzymywanie tymczasowych wersji obiektów, które można w razie potrzeby zatwierdzać lub odwoływać; · Możliwość dostosowywania modeli procesów polega na rozszerzaniu zestawu atrybutów modeli procesów, wprowadzaniu nowych obiektów i łączeniu ich z już istniejącymi. Biorąc pod uwagę przytoczone zasady i cechy, w toku badań opracowano model informacyjny procesów i obiektów ich otoczenia (rys. 5). Ryż. 5. Współzależność głównych obiektów środowiska procesowego. W oparciu o wygenerowany model informacji podsystem opisu procesów umożliwia rozwiązywanie następujących głównych zadań: · stworzenie holistycznego sformalizowanego modelu działalności TU; · aktualizowanie informacji o działaniach; · generowanie raportów i zaświadczeń o dokumentowaniu działalności PT. Podsystem kontroli realizacji procesów zapewnia realizację sformalizowanych procesów, routing zadań pomiędzy wykonawcami zgodnie z opisem, monitorowanie przestrzegania terminów i efektywności realizacji, przekształcanie danych o realizacji procesów ze źródeł zewnętrznych do jednego ujednoliconego formatu.0 W wyniku przeprowadzonych badań opracowano cykl życia procesów i operacji (rys. 6), który wraz z zapisem opisu procesów zapewnia rozwiązanie następujących zadań: · organizacja realizacji procesów; · monitorowanie i zarządzanie realizacją procesów; · organizacja kontroli nad realizacją procesów w punktach krytycznych; · tworzenie raportów analitycznych dla menedżerów różnych szczebli specyfikacji technicznych (szefowie sektorów, departamenty, departamenty, top management). Ryż. 6. Koło życia realizacja procesu Podsystem kosztów procesów przeznaczony jest do obliczania charakterystyk kosztowych procesów i ich analizy w różnych przekrojach, udostępnia narzędzia do szczegółowej analizy charakterystyk kosztowych procesów, bilansowania, analizy porównawczej, różne opcje obliczenie. Podsystem analizy działalności realizuje wsparcie analizy działalności PT w różnych aspektach – wydajności, kosztów, personelu, procesów itp., przy jednoczesnym zbieraniu i strukturyzacji danych ze źródeł zewnętrznych i innych podsystemów. Podsystem analityczny zbudowany jest w oparciu o metodologię CPM, z uwzględnieniem zadań Banku Rosji i dostarcza zestaw aplikacji analitycznych i narzędzi do rozwiązywania następujących zadań: .Zarządzanie systemem celów strategicznych, zadań i wskaźników (z uwzględnieniem celów wyznaczonych na poziomie federalnym przez Bank Rosji); .Wsparcie podejmowania decyzji w zakresie zarządzania personelem i strukturą organizacyjną PT; .Monitorowanie i analiza wskaźników efektywności. System celów strategicznych, celów i wskaźników to system zrównoważonych kart wyników (BSC) i kluczowych wskaźników wydajności, które można ustawić dla procesów, działów, pracowników itp. Wszystkie cele, zadania i wskaźniki mają charakter chronologiczny. Źródłem danych BSC jest hurtownia danych. Docelowe wartości wskaźników można ustalić za pomocą kilku scenariuszy, aby ocenić stopień realizacji celów i zadań, wskaźnikom można przypisać czynniki ważenia. Na podstawie porównania wartości docelowych i rzeczywistych prowadzony jest monitoring i analiza realizacji celów. Wspomaganie decyzji w zarządzaniu personelem obejmuje aplikacje analityczne do analizy struktury organizacyjnej, analizy personalnej pod kątem dyscypliny wydajnościowej, wydajności i kluczowych wskaźników wydajności procesów, równoważenia i podziału odpowiedzialności funkcjonalnej. Monitorowanie i analiza wskaźników wydajności odbywa się za pomocą narzędzi BI opartych na repozytorium, zapewniając jednocześnie możliwość porównywania wskaźników heterogenicznych i różnych rodzajów analiz (dynamiczna, strukturalna, porównawcza, klastrowa, rankingowa itp.). 2.2.3 Opracowanie DSS na poziomie specyfikacji technicznych, który wdraża rozwiązania metodologiczne i instrumentalne W trakcie rozwoju DSS przeprowadzono analizę wymagań dotyczących budowy systemu, opracowano logiczną i fizyczną strukturę danych, uzasadniono podstawowe zasady budowy systemu oraz zadania doboru technologii informatycznych do realizacji system został rozwiązany. Struktura systemu obejmuje podsystemy funkcjonalne realizujące logikę biznesową i interfejs użytkownika oraz podsystemy technologiczne zapewniające działanie podsystemów funkcjonalnych w oparciu o ujednolicone mechanizmy zarządzania danymi i scentralizowane metadane. Do wdrożenia systemu zostały wybrane następujące technologie informatyczne: · jako podstawa przechowywania informacji - system zarządzania relacyjnymi bazami danych Oracle wersja 9i; · jako środowisko rozwoju oprogramowania i narzędzi – kompleks analityczny „Prognoz-5”, ukierunkowany na rozwój systemów informacyjno-analitycznych oraz systemów wspomagania decyzji w różnych dziedzinach gospodarki; · do tworzenia komponentów webowych - zintegrowane środowisko Microsoft Visual Studio 2005 oraz platforma ASP.NET. Podczas tworzenia DSS opracowywany jest zestaw oprogramowania i rozwiązań technologicznych w oparciu o ujednolicone zasady architektoniczne dla najbardziej optymalnego i niezawodnego działania. Opracowując procedury zarządzania złożoną bazą danych, w tym segmentami transakcyjnymi i analitycznymi, opracowano i zastosowano następujące rozwiązania: · Dbając o spójność danych segmentu transakcyjnego i analitycznego bazy danych, w tym celu opracowano system połączonych ze sobą klas, skoncentrowany na wykorzystaniu zunifikowanego rdzenia przetwarzania transakcji, który opiera się na wykorzystaniu metadanych Oracle DBMS. Na poziomie tabeli kontrolę integralności danych zapewniają narzędzia DBMS w celu poprawy niezawodności działania (rys. 7): Ryż. 7. Schemat zarządzania spójnością danych DSS. · Wsparcie wersjonowania obiektów przy zachowaniu kontroli integralności na poziomie DBMS. W tym celu każdy obiekt jest przechowywany w dwóch tabelach: tabeli obiektów i tabeli wersji obiektów; · Skalowalność bazy danych na poziomie atrybutów i obiektów z kontrolą integralności. W przypadku dodatkowych atrybutów integralność jest kontrolowana na poziomie wyzwalacza; gdy w tabelach tworzone są nowe obiekty, wyzwalacze ujednoliconej kontroli integralności są tworzone automatycznie; · Optymalizacja ekstrakcji i zapisywania do bazy danych dużych ilości danych. Po utworzeniu struktury fizycznej została ona zindeksowana, dla tabel hurtowni danych wykorzystano narzędzia do tworzenia partycji systemu Oracle DBMS. Źródłami danych do wstępnego wypełnienia DSS i późniejszej aktualizacji mogą być dane ze standardowych systemów oprogramowania eksploatowanych w TU: Systemy Aktywności w Gospodarstwie (IEA), Systemy Zarządzania Dokumentacją, Systemy Automatyki itp. DSS umożliwia pobieranie opisów procesów z plików MS Word i Excel, które są ważne dla instytucji terytorialnych, które mają projekty modeli procesów „na papierze”. Opracowany DSS jest wykorzystywany w trybie przemysłowym w Narodowym Banku Republiki Baszkirii na ponad 300 stanowiskach pracy menedżerów i specjalistów do opisywania procesów, organizowania i monitorowania realizacji procesów, uzasadniania zmian w strukturze organizacyjnej oraz analizowania działań. W systemie opisano około 980 procesów, około 730 zaakceptowanych, około 200 procesów jest regularnie uruchamianych w trybie przemysłowym. 2.3Wnioski i wyniki stosowania niniejszego DSS Uzyskano następujące główne wyniki i wnioski: Na podstawie ustaleń przedstawiono koncepcję zintegrowanego systemu wspomagania decyzji w zarządzaniu działalnością TS, ukierunkowaną na integrację podejść BPMS, BI i CPM, w której opracowane przez autora metody i algorytmy budowane są na podstawie w oparciu o jednolite środowisko informacyjne i instrumentalne. Koncepcja łączy w sobie zarówno nowe, jak i dotychczas znane metody monitorowania i analizowania działań instytucji technicznych w oparciu o podejście procesowe, dostosowane do specyfiki Banku Rosji. Stworzono i przetestowano system wspomagania decyzji w określonych specyfikacjach technicznych Banku Rosji w zakresie zarządzania działalnością instytucji terytorialnej na poziomie regionalnym. Wykorzystanie DSS w specyfikacjach technicznych umożliwia zwiększenie zarządzania działaniami w oparciu o podejście procesowe, usprawnienie systemu kontroli wewnętrznej, optymalizację istniejącej struktury organizacyjnej oraz stworzenie repozytorium opartego na wskaźnikach efektywności. W wyniku wdrożenia systemu osiągnięto następujące wyniki (jak wynika z raportów do kierownictwa Banku Rosji): · ulepszony system wewnętrznej kontroli działań; · udoskonalono technologie wydawania i transakcji gotówkowych oraz obniżono koszty pracy (do 10% w przypadku niektórych transakcji); · centralizacja funkcji realizowanych przez Centra Rozliczeniowo-Kasa (13 funkcji w 9 procesach); · dział obiegu gotówki został przekształcony w dwa niezależne działy; · redystrybuowane stanowiska pomiędzy departamentami w ramach departamentu bezpieczeństwa i ochrony informacji; · przeprowadzono redukcję personelu w dziale ekonomiczno-operacyjnym; przygotowywane są propozycje optymalizacji przepływu pracy. Wniosek Do tej pory nie ma uznanego lidera w produkcji oprogramowania do budowy systemów DSS. Żadna z firm nie produkuje gotowego rozwiązania, które nazywa się „po wyjęciu z pudełka”, nadającego się do bezpośredniego wykorzystania w procesie produkcyjnym klienta. Tworzenie DSS zawsze obejmuje etapy analizy danych i procesów biznesowych klienta, projektowania struktur magazynowych z uwzględnieniem jego potrzeb oraz procesów technologicznych. Biorąc pod uwagę ilość zaangażowanych środków finansowych i innych, złożoność i wieloetapowość projektów budowy systemów DSS, wysoki koszt błędów projektowych jest oczywisty. Błędy w doborze oprogramowania mogą skutkować kosztami finansowymi, nie wspominając o wydłużeniu czasu projektu. Błędy projektowe struktury danych mogą prowadzić zarówno do niedopuszczalnej wydajności, jak i kosztu czasu poświęconego na ponowne ładowanie danych, który czasami sięga kilku dni. Dlatego mając dogłębne zrozumienie architektury hurtowni danych, konieczne jest unikanie wszelkich błędów, co pociąga za sobą znaczne skrócenie czasu realizacji projektu i możliwość maksymalnego wykorzystania wdrożenia DSS. Oddzielnie należy zaznaczyć, że problematyka podejmowania decyzji, a mianowicie DSS, są w naszym kraju słabo rozwinięte i mało wykorzystywane w praktyce. Korzystanie z programów takich jak ten tutaj opisany jest nie tylko bardzo proste, ale także dość efektywne i nie wymaga specjalnej wiedzy i inwestycji. Kilkadziesiąt różnych firm wytwarza produkty zdolne do rozwiązania niektórych problemów pojawiających się w procesie projektowania i eksploatacji systemów DSS. Obejmuje to DBMS, narzędzia do rozładowywania / przekształcania / ładowania danych, narzędzia do analizy OLAP i wiele innych. Samoanaliza rynku, badanie przynajmniej kilku z tych narzędzi nie jest zadaniem łatwym i czasochłonnym. Tak więc w tej pracy zapoznaliśmy się z systemami wspomagania decyzji. We wstępie uzasadniono aktualność tego tematu, podano cel i cele badania, ogólna charakterystyka pracy, zidentyfikowano przedmiot badania. W pierwszym rozdziale przedstawiono teoretyczne aspekty i koncepcje systemów wspomagania decyzji, szczegółową klasyfikację rodzajów DSS oraz wstępnie ujawniono ich funkcje. Również w tym rozdziale zapoznaliśmy się z historią powstawania systemów wsparcia, przeanalizowaliśmy bardziej szczegółowo strukturę DSS i jego główne elementy. są podane cechy charakterystyczne systemy wspomagania decyzji, a także obszary i obszary, w których można je zastosować. Zidentyfikowano metodologię wspomagania decyzji, co pozwala stwierdzić, że jej zastosowanie umożliwia: · sformalizować proces znajdowania rozwiązania na podstawie dostępnych danych (proces generowania opcji rozwiązania); · uszeregować kryteria i wydać oparte na kryteriach oceny parametrów fizycznych, które mają wpływ na rozwiązywany problem (umiejętność oceny rozwiązań); · stosować sformalizowane procedury koordynacyjne przy podejmowaniu decyzji zbiorowych; · stosować formalne procedury przewidywania konsekwencji podejmowanych decyzji; · wybierz opcję, która prowadzi do optymalnego rozwiązania problemu. Wynika z tego, że zapoznaliśmy się z podstawowymi rzeczami i częścią teoretyczną dotyczącą systemów wspomagania decyzji. W rozdziale drugim przedstawiono praktyczne wdrożenie DSS w zakresie zarządzania działalnością organizacji w oparciu o podejście procesowe (na przykładzie oddziałów terenowych Banku Rosji). Proponuje się koncepcję budowy DSS „Zarządzanie działalnością instytucji terytorialnych Banku Rosji”. Opracowano i uzasadniono model koncepcyjny DSS, strukturę funkcjonalną oraz wymagania dla głównych komponentów. Proponowany jest zestaw metod i narzędzi wspierających podejmowanie decyzji w zarządzaniu SP, z uwzględnieniem specyfiki Banku Rosji. Opracowano i uzasadniono wymagania dotyczące wsparcia informacyjno-analitycznego systemu z uwzględnieniem pilnych zadań zarządzania oddziałami terytorialnymi Banku Rosji. Podano wyniki wprowadzenia tego systemu na podstawie raportów dla kierownictwa Banku Rosji. W ten sposób dowiedzieliśmy się, jak te systemy wspomagania decyzji znajdują zastosowanie w praktyce – w naszym przypadku w sektorze bankowym. Zastosowanie DSS jest obiecujące choćby dlatego, że każda decyzja kierownictwa jest subiektywna, oparta na polityce firmy, odzwierciedla główne cele organizacji i, co najważniejsze, niekoniecznie jest prawdziwa. Wszystko to prowadzi do konieczności sformalizowania procesu decyzyjnego i pozyskania narzędzi wspierających, aby zmniejszyć ryzyko podjęcia błędnej decyzji. Ta ostatnia wzrasta wraz z nagromadzeniem informacji do przetworzenia. Dzieje się tak, ponieważ dana osoba albo nie jest w stanie przetworzyć wszystkich niezbędnych informacji do samodzielnego podjęcia decyzji, albo nie jest w stanie zrobić tego w czasie, gdy zadanie jest nadal istotne. Bibliografia 1.Vesnin, V.R. Zarządzanie: Podręcznik - wyd. 4, poprawione. oraz dodatkowe - M.: TK Velby, 2009r. - 342 s. 2.Gerchikova, IN. Proces podejmowania i wdrażania decyzji zarządczych / I.N. Gerchikova // Zarządzanie w Rosji i za granicą, 2013. Nr 12. - 130 s. .Goncharov, V. I. Kierownictwo: instruktaż/ V. I. Goncharow. - Mińsk: Nowoczesna Szkoła, 2010. - 255 pkt. .Drobyszew, A.V. Metody podejmowania decyzji. Metody Delphi i ELECTRA. - Wytyczne Do Praca laboratoryjna na kursie „Systemy wspomagania decyzji”. - MGIEM. Por.: I.E.Safonova,., K.Yu.Mishin, S.V.Tsyganov: M., MGIEM, 2008. - 26 s. .Evlanov, AG Teoria i praktyka podejmowania decyzji. - M.: Ekonomia, 2010. - 212 s. .Korotkov, E.M. Management: podręcznik dla kawalerów / E.M. Korotkov. Moskwa: Yurait, 2012.- 85 pkt. .Kriwko, O.B. Technologia informacyjna. Moskwa: SOMINTEK. 2011r. - 179 pkt. .Lafta, JK Efektywność zarządzania organizacją. - M .: Rosyjska literatura biznesowa, 2009. - 320 s. .Lafta, JK Efektywność zarządzania organizacją. - M .: Rosyjska literatura biznesowa, 2011. - 320 s. .Makarow, S.F. Menedżer w pracy. - M.: FINPRESS, 2009r. - 155 s. .Meskon, M. Podstawy Zarządzania: Podręcznik / M. Meskon, M. Albert, F. Hedouri; M., 2012. - 387 s. .Pankrukhina, A.P. Teoria kontroli: podręcznik / [Yu. P. Aleksiejew i inni]; pod redakcją naczelną: A. L. Gaponenko, A. P. Pankrukhina. - Moskwa: Wydawnictwo RAGS, 2010.- 213 s. .Pirożkow, W.A. O wdrożeniu procesowego podejścia do zarządzania w postaci systemu wspomagania decyzji „Zarządzanie działalnością organizacji” [Tekst] / V.A. Pirozhkov // Biuletyn Uniwersytetu Tambowskiego. Ser.: Nauki humanistyczne. - 2008r. - Wydanie. 11. - 489 pkt. .Poluszkin, O.A. Zarządzanie strategiczne: notatki z wykładów. - M.: EKSMO, 2007. - 138 s. władze regionalne // Reformy w Rosji i problemy .Romaszczenko, W.N. Podejmowanie decyzji: sytuacje i porady. - Kijów, 2012 r. - 154 pkt. 16.Rumyantseva Z.P. Zarządzanie organizacją: podręcznik. - M.: INFRA-M, 2005r. - 432 s. .Saraev, A. D., Shcherbina O. A. Analiza systemu i nowoczesne technologie informacyjne // Postępowanie Krymskiej Akademii Nauk. - Symferopol: SONAT, 2009. - 136 pkt. .Safonowa, tj. Metody podejmowania decyzji. Modyfikacja metody Delphi i metody analizy hierarchii. - Wytyczne do pracy laboratoryjnej na kursie „Systemy wspomagania decyzji”. - MGIEM. komp.:. 18. I. E. Safonova, A. V. Drobyshev, K. Yu Mishin, S. V. Tsyganov: M., MGIEM, 2007. - 20 s. .Safonowa, tj. Metody podejmowania decyzji. Metoda i metody minimalnych odległości MaxiMin i MaxiMax. - Wytyczne do pracy laboratoryjnej na kursie „Systemy wspomagania decyzji”. - MGIEM. Por.:, 18. IE Safonova A.V. Drobyshev, K.Yu. Mishin, S.V. Tsyganov: M., 2007. - 19 str. .Tereliański, P.V. Systemy Wspomagania Decyzji. Doświadczenie projektowe: monografia / P.V. Tereliański; VolgGTU - Wołgograd, 2009. -127 pkt. .Czerniachowskaja L.R. Wspomaganie decyzji w strategicznym zarządzaniu przedsiębiorstwem w oparciu o inżynierię wiedzy / L.R. Chernyakhovskaya i inni Ufa: Akademia Nauk Republiki Białoruś, Gilem, 2010. - 128 s.
Wysyłanie dobrej pracy do bazy wiedzy jest proste. Skorzystaj z poniższego formularza
Studenci, doktoranci, młodzi naukowcy korzystający z bazy wiedzy w swoich studiach i pracy będą Ci bardzo wdzięczni.
Podobne dokumenty
Badanie proces technologiczny do produkcji betonu komórkowego. Modeluj „jak to będzie” procesu diagnozowania stanu procesu technologicznego produkcji betonu komórkowego z uwzględnieniem systemu wspomagania decyzji. Prototypowanie interfejsu DSS.
praca dyplomowa, dodana 17.06.2017
Zbadanie celu i głównych zadań, które rozwiązuje Project Expert - system wspomagania decyzji (DSS) przeznaczony dla menedżerów projektujących model finansowy dla nowego lub istniejącego przedsiębiorstwa. Aplikacje programowe, etapy pracy.
streszczenie, dodane 19.05.2010
Klasyfikacja systemów informatycznych do zarządzania działalnością przedsiębiorstwa. Analiza rynku i charakterystyka systemów klasy Business Intelligence. Klasyfikacja metod decyzyjnych stosowanych w DSS. Wybór platformy Business Intelligence, kryteria porównawcze.
praca dyplomowa, dodana 27.09.2016
Klasyfikacja systemów wspomagania decyzji. Analiza porównawcza metody oceny ryzyka kredytów detalicznych. Struktura systemu wspomagania decyzji, tworzenie wyjściowej bazy wiedzy. Projektowanie bazy danych systemu informacyjnego.
praca dyplomowa, dodana 07.10.2017
Pojęcie systemów wspomagania decyzji. Zakres Analytica 2.0. Oprogramowanie do modelowania ilościowego. Graficzny interfejs do tworzenia modeli. Podstawowe metody modelowania. Diagram wpływu i drzewo decyzyjne.
prace kontrolne, dodane 09.08.2011
Rozwój algorytmiki i oprogramowania do rozwiązywania problemu wspomagania decyzji przy wydawaniu nowych produktów. Matematyczne wsparcie zadania wspomagania podejmowania decyzji o wypuszczeniu nowych produktów, główne dane wejściowe i wyjściowe.
praca dyplomowa, dodana 03.08.2011
Rodzaje administracyjnych systemów informacyjnych: systemy raportowania, systemy wspomagania decyzji, systemy wspomagania decyzji strategicznych. Sortowanie i filtrowanie list w Microsoft Excel. Praca z bazami danych w Microsoft Access.
test, dodany 19.11.2009
-
 Przewóz szafy przesuwnej we własnym zakresie lub z pomocą specjalistów
Przewóz szafy przesuwnej we własnym zakresie lub z pomocą specjalistów
-
 O podejściu do oceny apetytu na ryzyko firmy na podstawie sformalizowanej oceny jej kondycji finansowej Ustalanie i monitorowanie apetytu na ryzyko
O podejściu do oceny apetytu na ryzyko firmy na podstawie sformalizowanej oceny jej kondycji finansowej Ustalanie i monitorowanie apetytu na ryzyko
-
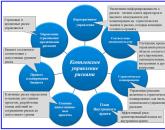 Budowanie systemów zarządzania ryzykiem Ocena skuteczności zarządzania ryzykiem dokonywana jest na podstawie:
Budowanie systemów zarządzania ryzykiem Ocena skuteczności zarządzania ryzykiem dokonywana jest na podstawie:
-
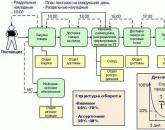 Złote zasady opisu procesów biznesowych
Złote zasady opisu procesów biznesowych
Popularny
- Wyznaczanie wielkości zużycia skumulowanego Zużycie skumulowane wyznaczone metodą multiplikatywną
- Obowiązki dyrektora finansowego
- Rok Międzynarodowych Standardów Sprawozdawczości Finansowej
- Opis stanowiska dyrektora finansowego
- Aspekty prawne i zagadnienia popytu na finansowanie projektów Cechy finansowania projektów banków komercyjnych
- Organizacja budżetowania w przedsiębiorstwie
- Szybkość wiercenia studni
- Asynchroniczny napęd elektryczny o zmiennej częstotliwości - cykl wykładów Zautomatyzowany napęd elektryczny - cykl wykładów
- Asynchroniczny napęd elektryczny o zmiennej częstotliwości - przebieg wykładów
- Instrukcja obsługi stojaka na